7 min to read
버그 트래킹 일지(1) - 시작은 사전지식 확보부터
주니어개발자의 버그 트래킹 일지입니다!
주 내용은 웹 서비스의 세션을 Membase(현재의 Couchbase)로 관리하면서 발생한 이슈입니다. 이슈를 해결해 나가는 과정을 기록으로 남깁니다.
버그 트래킹 일지(1) - 시작은 사전지식 확보부터
버그 트래킹 일지(2) - 로그를 보자!
버그 트래킹 일지(3) - 임시방편보단 장기적으로
버그 트래킹 일지(4) - 의심하고 또 의심하자
버그 트래킹 일지(5) - 대망의 적용 배포 그리고 결론
버그트래킹 환경
-
Membase Server
- Version : 1.7.2
-
Node
- 4개
- 노드당 Replica 2개
- 노드당 할당 메모리 2GB
-
Bucket
- 1개
- 메모리 8GB(노드당 메모리 * 노드 수)
-
각 서버 스팩
- RAM 8GB
- HDD 30GB
-
WEB Server
- Spring Boot Web Application(version 1.2)
- SpyMemCached(version 2.7.3)
- Spring Boot Web Application(version 1.2)
버그트래킹의 시작은 사전지식 확보부터
버그 트래킹을 할 때 알고 있는 지식 내에서 발생한 이슈라면 좋겠지만, 대부분의 버그는 알고 있지 않은 부분에서 시작됩니다. 그렇기때문에 버그를 트래킹할 때 무작정 달려들기 전 전반적인 사전지식의 확보가 필수라고 생각했습니다.
그래서 첫번째로 저는 Spring에서 Membase를 세션관리로 사용할 때 알고 있어야할 지식들을 조사했습니다.
모든 것을 알 수 없기때문에 의심이 됐던 , 그리고 불확실했던 지식들만 빠르게 습득하였습니다!
조사한 사전 지식
CouchBase(Membase)
1. Bucket
Couchbase Server 클러스터의 물리적 리소스의 논리적 그룹
종류
- Couchbase
- 영구 및 복제 서비스를 제공하여 높은 가용성과 동적 재구성 가능한 분산 데이터 스토리지를 제공
- Memcached
- 직접 주소 지정 (확장)은 분산 메모리에 키와 값의 캐시를 제공
- 버킷은 관계형 데이터베이스 기술과 함께 사용하도록 설계
주요 기능
- Rebalancing
- 자원과 동적 추가 또는 클러스터의 버킷과 서버 제거 간 부하 분산을 가능하게 함
- Replacing
- 복제 서버 설정 가능한 수는 Couchbase(Membase) 유형 버킷의 모든 데이터 객체의 복사본을 받을 수 있습니다. 호스트 시스템에 장애가 발생한 경우, 복제 서버가 Fail Over를 통해 avilability 클러스터 작업을 제공하고 호스트 서버로 승격 할 수 있습니다. 복제가 버킷 레벨로 설정되어 있습니다.
vBucket
- 실제데이타와 물리서버간의 맵핑을 관리
- 각 키가 어디에 저장되어 있는지를 vBucket이라는 단위로 관리
- 키에 대한 해쉬값을 계산한 후에, 각 해쉬값에 따라서 저장되는 vBucket을 맵핑한다음 각 vBucket을 노드에 맵핑
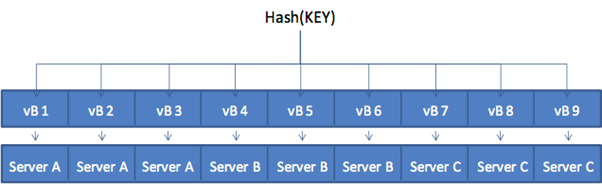
출처 : http://docs.couchbase.com/couchbase-manual-2.5/cb-admin/#vbuckets
2. Node
- Couchbase(Membase)는 여러 개의 노드로 이루어진 클러스터로 구성
- 물리적인 서버에서 기동하는 하나의 Couchbase(Membase) 인스턴스
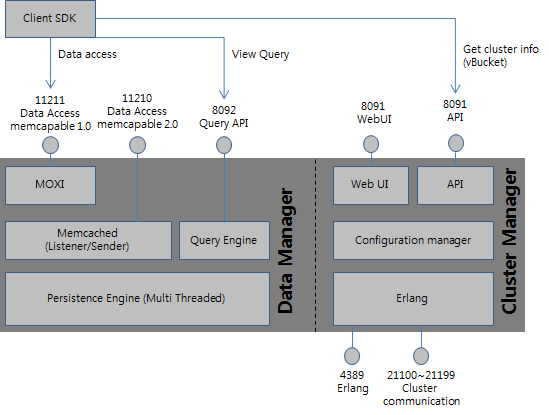
출처 : http://hamait.tistory.com/198
Cluster Manager
- 8091 포트의 REST API를 통해서, 설정 정보와 vBucket 정보를 읽어옴
Data Manager
- 직접 데이터에 접근하는 부분
- 윗단에는 memcached가 있으며, 데이터를 cache하는데 사용
- Memcached 위에는 moxi가 Proxy로 사용
데이터 쓰기, 복제
- Client SDK를 통해서 쓰기 요청
- 해쉬 알고리즘에 따라 데이터의 키 값에 맵핑 되는 vBucket을 탐색
- vBucket에 맵핑 되는 노드를 찾아서 쓰기 요청
- 쓰기 요청은 해당 노드의 Listener로 전달
- 들어온 데이터를 로컬의 캐쉬에 씀
- 클러스터의 다른 노드로 복제 요청
- 노드의 디스크에 데이터 저장
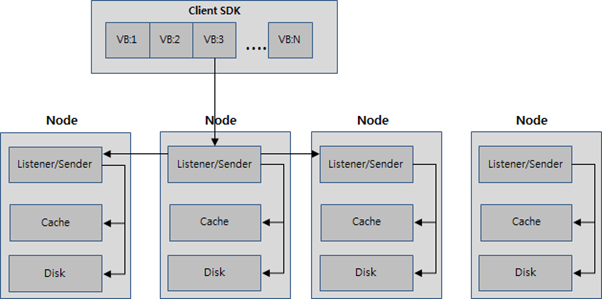
출처 : http://hamait.tistory.com/198
3. Rebalancing
- 새롭게 배치된 데이터에 따라서 vBucket to 노드간의 데이터 맵핑 정보 업데이트
- 노드가 클러스터에 추가되거나, 장애등의 이유로 삭제되었을 때 물리적으로 데이터가 다른 노드로 다시 분산 배치
- 노드간에 데이터 복제가 심하게 일어나기 때문에, 리밸런스는 부하가 적은 시간대에 하도록 권장
4. FailOver
Failover는 Couchbase(membase) 클러스터의 노드에서 수행되며 이는 비정상이고 더 이상 도달 할 수없는 노드에서 수행됩니다. 그 목적은 비정상적인 노드를 제거하고 다른 노드에서 복제본 데이터를 사용 가능하게하여 클러스터를 일관된 상태로 만드는 것입니다.
Failover의 동작은 아래와 같습니다.
- 클러스터의 새로운 토폴로지로 업데이트 된 클러스터 맵을 수신
- 새로운 설정에 적응
- 현재 활성 구성과 비교
- 어떤 TCP 연결 및 자원을 종료 및 제거해야하는지 결정
- 장애 조치 노드에서 처리하는 복제 된 데이터가 클러스터의 다른 노드에서 활성화
공식 홈페이지에서는 FailOver 동작에 대해 아래의 경고를 제공합니다.
When a node is removed from the cluster during failover, it's possible for operations to be in mid-flight as a request or response from the server or being processed on the server. This means that the underlying TCP connection executing the operation may be closed by the server or the client which would result. In most cases this will result in that operation failing with either a with a client or server IO exception. In certain cases the operation will be retried up until it's configured operation "lifespan". It may be retried multiple times and fail multitple times until it either succeeds to or times out. In the event of a timeout, an OperationTimeoutException will returned in the Exception field of the IOperationResult.
위의 동작 과정 등이 리소스에 어느 정도 영향을 미치므로, 아래의 Exception들이 발생할 수 있다고 합니다.
- OperationTimeoutException
- NodeUnavailableException
- ConnectionUnavailableException
Auto FailOver
Auto Fialover는 설정해준 시간을 주기로 각 노드 서버의 상황을 확인하고, 해당 노드 서버가 장애라고 판단되면 해당 서버를 FailOver 시켜주는 옵션입니다.
- 세 개 이상의 노드가 포함 된 클러스터에서만 사용 가능
- Default는 사용하지 않도록 비활성화
- 모든 노드 연쇄 FailOver를 방지하기 위해 하나의 노드까지만 자동 장애 조치
- 지정된 지연 기간 내에 두 개 이상의 노드가 동시에 다운되면 자동 장애 조치를 하지 않음
- 확인 주기는 최소 30초
참고 : Couchbase Administrator Guide
참고 : 카우치베이스(Couchbase) 서버-#6 아키텍쳐 구조 살펴보기 : 조대협의 블로그
Spring Security
- 인증(Authentication)과 권한부여(Authorization)를 담당
- 세션 정보의 존재 여부에 따라 인증을 판단
- 사용자의 보호 및 인증된 세션을 SecurityContext에 저장
1. SecurityContextPersistenceFilter
SecurityContext를 로드하고 저장하는 역할을 담당
2. SecurityContextRepository
SecurityContextPersistenceFilter에서SecurityContext가 저장될 저장소와의 통신과 관련된 기능을 담당MemcachedSecurityContextRepository(자체 구현) 사용
SessionObject를 생성 인자로 갖음
3. SpyMemcached
클라이언트단에서 Couchbase(Membase)와 통신을 지원하는 오픈소스 클라이언트 SDK
4. MemcachedClient
- Couchbase(Membase)의 정보 및 통신과 관련된 기능을 담당
- 생성 인자로 Bucket 생성에 필요한 정보(server list, bucket name, pwd)를 갖음
5. Session
Session정보를 생성, 변경 및 로드하는 역할을 담당MemcachedSession(자체 구현) 사용
SecurityContextRepository의 생성인자로SecurityContextRepository에 유일한 객체로 생성 됨
이렇게 첫번째 사전 지식을 확보했습니다. 이제 본격적인 원인 분석에 들어갈 수 있습니다.
사전지식의 확보로 간단한 문제에 대한 결론도 낼 수 있었습니다.!
어플리케이션 다운 사태
리벨런싱 도중 어플리케이션 다운
리벨런싱이 많은 리소스를 사용하므로, 트래픽이 많은 상황에서 피해야 한다는 경고는 알고 있습니다. 그러나 리벨런싱 상황에 Membase Server가 죽은 것이 아닌 어플리케이션이 죽은 상황에 대해서는 정확한 파악이 필요해보였습니다.
결론부터 이야기하자면 원인은 Main Thread의 StackOverFlow 입니다.
Exception in thread "Memcached IO over {MemcachedConnection to xxxxxxxxxxxxxxxxxxxxxxx}" java.lang.StackOverflowError
at net.spy.memcached.ops.MultiOperationCallback.complete(MultiOperationCallback.java:33)
...
at net.spy.memcached.ops.MultiOperationCallback.complete(MultiOperationCallback.java:33)
Memcached는 vBucket을 기반으로 해당 데이터가 어디에 있는지 판단을 하게 됩니다. vBucket을 통해 데이터를 탐색할 때 뱉게되는 Error로 WARN Level로 로깅되는 NOT_MY_BUCKET이란 것이 있습니다. 해당 Error는 해당 vBucket에 데이터가 없을 경우 경고를 띄운 뒤 재귀 탐색을 통해 다른 vBucket으로 데이터를 탐색하는 로직을 가지고 있습니다.
리벨런싱 작업이 수행될 때 수많은 데이터가 vBucket에서 제외되어 데이터를 분배하는 복잡한 과정이 수행됩니다. 이 과정 중간에 특정 데이터를 요청했을 때 해당 데이터가 리벨런싱 과정 중 vBucket에서 제외되었다면, vBucket 안에 데이터가 자리 잡을 때까지 재귀탐색을 하게 되며, 리벨런싱 되야하는 데이터양이 많은 경우 이 작업에 긴 시간이 생기며, 그 긴 시간동안 MainThread에서는 엄청나게 빠른 속도로 재귀 탐색을 하다 결국 StatckOverFlow Error를 뱉게 되는 상황이였습니다.
해당 문제의 해결방법은 Couchbase에서 경고하듯, 트레픽이 적은 시간대에 최대한 빠르게 리벨런싱을 수행하는 방법뿐이 없다고 판단됩니다.
아마 Membase와 Spring의 Session의 모든 것을 공부하려면, 몇주 혹은 몇달이 소요될 수도 있었을 것 입니다. 의심이 됐던 , 그리고 불확실했던 지식들만 빠르게 습득하는 것이 중요할 것 같습니다.
다음에 계속..버그 트래킹 일지(2) - 로그를 보자!

Comments