17 min to read
BentoML 을 활용하여 딥러닝 모델 API 서빙하기
![]()
안녕하세요. 부설연구소 & 빅데이터팀 Data Intelligence 파트의 류혜정입니다. 최근 줌포털 투자탭에 적용하기 위해 개발한 ‘투자줌 뉴스 카테고리 분류 모델’을 BentoML 로 패키징하여 서빙한 경험에 대해 공유하고자 합니다. 😇
0. 모델 배포와 서빙을 더 효율적으로

BentoML 의 공식 깃허브에서는 BentoML 을 아래와 같은 한 문장으로 소개하고 있습니다.
“BentoML enables users to create a machine learning powered prediction service in minutes and bridges the gap between data science and DevOps.”
이 중에서도 “bridges the gap between data science and DevOps” 부분이 핵심이 아닐까 생각합니다. 말 그대로, 데이터 사이언티스트가 자신이 개발한 모델을 배포 및 서빙하는 과정을 효율적으로 처리할 수 있게끔 해주는 것이죠.
과거에는 데이터 사이언티스트가 개발한 모델을 DevOps, 백엔드, 서버 엔지니어링 파트로 전달하여 서빙하는 경우가 많았으나, 최근 들어서는 데이터 사이언티스트 스스로가 이러한 역량을 갖추어야 할 필요성이 증가하고 있는 것 같습니다. DevOps 조직의 입장에서도, 데이터 사이언티스트의 입장에서도 분명 그편이 더욱 효율적이기 때문입니다.
모델의 서빙만을 담당하게 되는 DevOps 조직은 모니터링 중 시스템에 문제가 발생하더라도 인공지능 모델 내부적인 원인을 곧바로 해결할 수는 없습니다. 그런 상황에서는 시스템에 문제가 발생할 때마다 ‘문제 발생 파악 → 데이터 사이언스(DS) 조직에 시스템 점검 요청 → DS 담당자의 모델 소스 점검 및 수정 → DevOps 담당자에게 모델 리패키징 및 재배포 요청 → DS 담당자 배포된 모델 기능 확인’ 등에 해당하는 몇 단계 절차를 거쳐야만 할 것입니다. 반면, 데이터 사이언티스트가 모델 서빙을 책임지고 담당한다면 업무가 조직과 조직 사이를 거쳐다닐 필요없이 한 팀, 혹은 한 사람 내에서 온전히 해결될 수 있을 테죠. 많은 커뮤니케이션 비용을 절약할 수 있을 것입니다.
또 데이터 사이언티스트의 입장에서는, DevOps 조직의 업무 일정에 자신의 프로젝트 일정을 맞추어야만 하기 때문에, 모델 개발을 모두 끝내고서도 서비스에 곧바로 적용하지 못하고 불필요하게 대기해야만 하는 상황이 발생할 수 있습니다. 실제로 이러한 대기 지연은 종종 발생하는 편입니다. DevOps 조직은 그 업무 특성상, 전체 개발실의 다양한 팀으로부터 항시 시급한 업무 요청을 받고 있기 때문입니다. 긴 지연은 아니라고 하더라도, 보통 인공지능 모델은 새로운 데이터로 학습한 버전을 런칭 이후에도 지속적으로 갱신해주어야 하기 때문에 이러한 문제가 계속해서 반복되면 생각보다 큰 비용 낭비가 됩니다.
0-1. Components of BentoML
BentoML 을 구성하는 핵심적인 컴포넌트와 그 기능을 간략히 정리해보자면 아래와 같습니다.
- BentoService
- BentoService 는 BentoML 을 이용하여 모델의 추론 서비스(prediction services)를 빌딩하는 가장 기본적인 컴포넌트입니다. 모델이 어떤 artifacts 들로 구성되어 있는지, 어떤 환경이 준비되어야 하는지 등 모델의 prediction 실행을 위해 필요한 모든 내용을 요약하여 담고 있는 하나의 유닛을 가리킵니다.
- Model Artifacts
- BentoML 은 Model 의 종류에 따라 (예를 들어, Transformers 라이브러리로 개발되었는지, sklearn 로 개발되었는지 등) 최적화된 artifacts 로 패키징할 수 있습니다. Model 의 알멩이라고 할 수 있는 artifacts 에는 대표적으로 model weight file, tokenizer 등이 포함됩니다.
- API Functions and Adapters
- 위에서 언급한 BentoService 는 python 스크립트에서 Class 의 형식으로 구현되는데, 그 아래 predict 함수와 @api 데코레이터를 통해 API 객체를 선언할 수 있습니다. 이렇게 선언한 API 는 Adapters 를 통해 입출력 형식, 배치 여부, 최대 사이즈, 최대 Latency 등 상세한 스펙 사항을 정의해줄 수 있으며, 입력 받은 데이터가 어떤 추론 로직을 거쳐야하는지에 대한 정의도 여기에 함께 포함됩니다.
- Model Management & Yatai
- BentoML 에서는 Yatai 라는 Model Management Component 와의 연동을 공식적으로 지원합니다. GitHub 이나 GitLab 와 비슷하게, 인공지능 모델의 저장소 역할을 하는 것이라고 이해하면 쉽습니다.
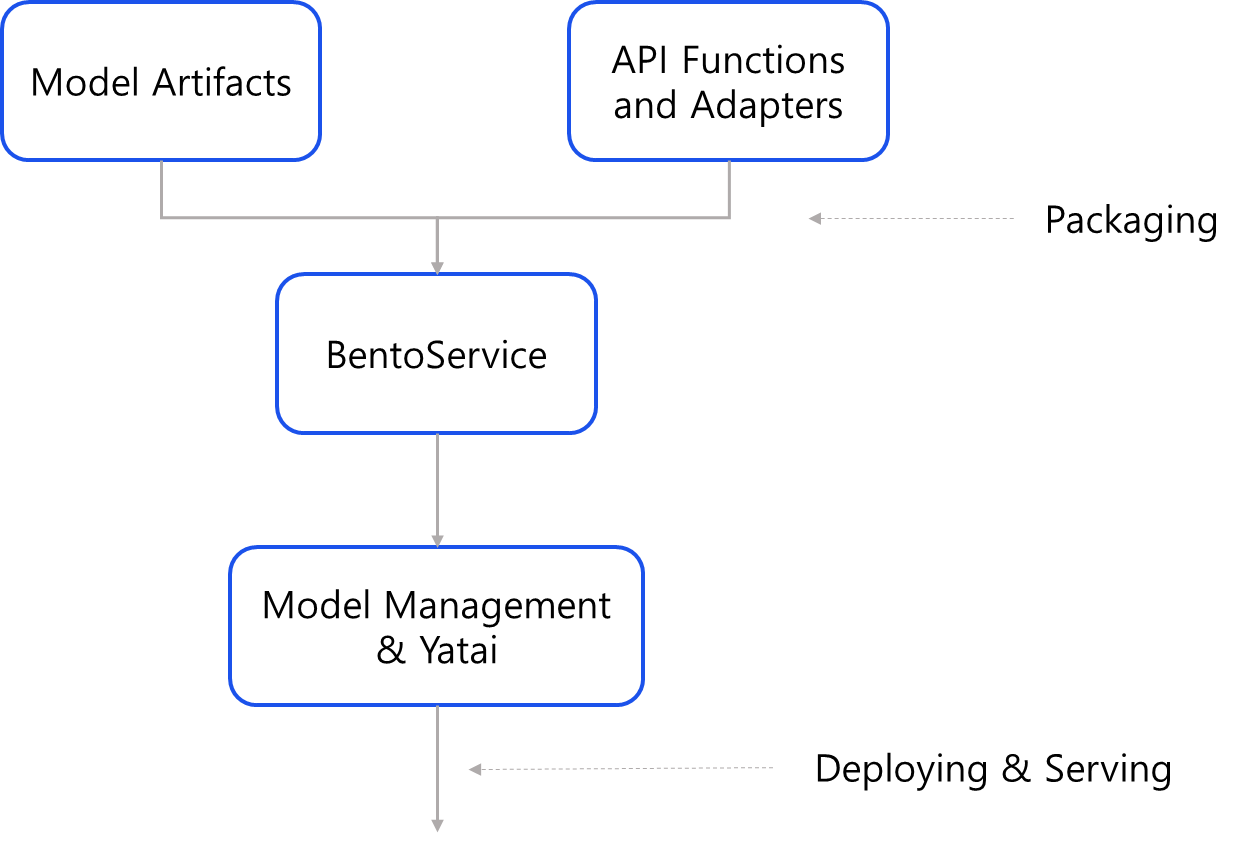 BentoML 핵심 컴포넌트들의 대략적인 흐름도
BentoML 핵심 컴포넌트들의 대략적인 흐름도
그리고 이러한 BentoML 의 컴포넌트들은 투자줌 뉴스 카테고리 분류 모델 개발 중, 아래와 같은 면에서 비효율성을 개선하는데 중점적으로 도움이 되었습니다.
Docker
ML/DL 모델 뿐만 아니라 거의 대부분의 개발 프로젝트가 도커를 기반으로 배포되고 있습니다. 내가 개발한 모델이 실서비스에 서빙되기 위해서는 반드시 시스템이 도커라이징(Dockerizing) 되어야만 하는 것입니다. requirements.txt 에 시스템을 위한 패키지들을 정리하고, Dockerfile 을 작성하여 이미지를 빌드하는 등 도커라이징을 위한 일련의 과정을 거쳐야만 하죠. 뒤에서 더욱 자세한 내용이 나오겠지만, BentoML 은 이러한 도커라이징 과정을 매우 적은 양의 코드만으로 처리할 수 있도록 해줍니다.
API
저의 경우, 모델을 배치 프로세스(오프라인 서빙)가 아닌 API 형태(온라인 서빙)로 제공해야 하는 프로젝트가 많았습니다. BentoML 을 사용하기 이전에는 (대부분 사내 서비스용이었기 때문에) 주로 flask 와 gunicorn 을 결합하여 API 를 개발해왔는데, 난이도가 높은 축에 속하는 작업은 아니나, BentoML 에서는 @api 데코레이터 하나로 매우 간단히 해결할 수 있는 부분이었습니다.
Swagger UI (데모 페이지)
모델을 개발하고 나면, 모델의 성능 또는 추후 고도화 방향성에 대한 피드백을 구하기 위해 결과물을 기획팀 담당자분께 공유 드립니다. 기획자분들이 원하는 때 편리하게 모델을 테스트해보실 수 있도록 웹 UI (기획팀과는 데모 페이지라고 통용하여 부르고 있습니다.) 를 별도로 제공해야합니다. 저는 flask 와 Django 두 가지를 사용해본 경험이 있는데, API 객체를 Swagger UI 와 별도로 연동시켜 주어야 한다는 점이 조금 비효율적으로 느껴졌습니다. BentoML 에서는 이를 위한 과정을 별도로 거치지 않아도 API 와 연동된 Swagger UI 를 디폴트로 제공합니다.
그래서 BentoML 이란
사실 BentoML 의 Bento(벤또) 는 도시락을 말하는 일본어입니다. 이름에서부터 짐작할 수 있듯이, ML/DL 모델과 모델을 서빙하기 위한 일련의 주변 코드들을 도시락처럼 차곡차곡 패키징하여 유저에게 제공한다는 의미를 담고 있는 것이죠. 아래의 그림과 같이 말입니다.
, BentoML: Create an ML Posered Prediction Service in Minutes](/images/lab/post/2022-02-21-BentoML/1_Q_gi8bLO6NmSXKY-x5D9jg.png) 이미지 출처: towardsdatascience.com, BentoML: Create an ML Posered Prediction Service in Minutes
이미지 출처: towardsdatascience.com, BentoML: Create an ML Posered Prediction Service in Minutes
1. BentoML 을 알게 된 경로
1-1. 구글링
위와 같은 어려움을 해결하기 위해 당연히 가장 먼저 시도했던 방법은 구글링입니다. 그러나 MLOps 라는 분야 자체가 대두된지 얼마되지 않아, 구글링만으로는 원하는 만큼 상세한 정보를 얻지 못했습니다. MLOps 에 대해 설명하는 체계적인 문서는 많이 찾을 수 있었지만, 제가 알고 싶은 것은 ‘그래서 춘추전국시대라고 불릴만큼 수많은 MLOps 툴 중에 무엇을 사용하는 것이 나의 경우에는 가장 효율적일까’였기 때문입니다. 진짜 트렌드를 파악하기 위해서는 해당 기술을 활발히 사용하고 있는 실제 개발자들의 이야기를 들어보는 것이 무엇보다 중요하다는 생각이 들었습니다.

1-2. Reddit, Facebook page, KakaoTalk 오픈채팅방
저와 같은 고민을 하고 있는 사람, 혹은 비슷한 고민을 거쳐 현재 활발하게 MLOps 툴을 활용하고 있는 사람들이 모여 있는 곳을 찾고 싶었습니다. 그래서 저는 MLOps 주제와 관련된 Reddit, Facebook page, KakaoTalk 오픈채팅방에 참여하여 약 한달 여간 개발자분들이 나누는 이야기를 지켜보았습니다. 그리고 제가 겪고 있는 (위에서 언급한) 비효율을 해결하기 위한 수단으로서는 모델 서빙에 특화된 가벼운 라이브러리인 BentoML 이 가장 적합하다고 판단했습니다.

2. 모델 설명
2-1. 목적
줌 투자탭 오늘의 뉴스에 노출되는 기사들의 카테고리 재분류를 통해 1차 분류(별도의 시스템입니다.)에서 오분류된 결과가 오늘의 뉴스에 노출되는 것을 최소화하는 것이 투자줌 뉴스 카테고리 분류 모델의 목적입니다.
2-2. 활용 데이터
투자줌 뉴스 카테고리 1차 분류 시스템의 분류 결과를 기획팀에서 정제하여 분류 학습 데이터셋을 구축했습니다.
- 1차 분류 시스템 → 오분류 케이스 제거 → 학습 데이터셋
2-3. 개발 스펙
- python (BentoML 은 python 3.6 이상을 지원합니다.)
- bentoml
- torch
- pytorch lightning
- onnx & onnxruntime
- huggingface 의 transformers
- nvidia-docker
- kafka-python
- etc
3. 프로젝트 진행 과정
3-1. pytorch lightning → onnx
BentoML 은 현재 공식적으로 pytorch lightning 모델에 대한 패키징 기능을 지원하고 있지만, 제가 개발한 모델에 대해서는 지속적으로 특성 구성 요소에 대해 패키징 오류가 발생했습니다. BentoML 깃헙 이슈와 공식 슬랙 채널을 모두 살펴보았지만 아직까지 해결되지 않은 이슈인 듯 보여 pytorch ligntning 으로 개발한 모델을 onnx 로 우선 exporting 하였습니다.
3-2. onnx → bento bundle
3-2-1. bentoml 설치
bentoml 을 pip 를 이용해 간단히 설치할 수 있습니다.
$ pip install bentoml
3-2-2. main.py
onnx 로 export 한 모델은 main.py 파일을 작성하여 bento bundle 로 패키징할 수 있었습니다. (여기서 bento bundle 이란 BentoML 을 사용하여 패키징한 모델 파일과 코드들의 뭉치(?)를 이르는 용어입니다.)
# main.py
onnx, transformers 등 필요한 라이브러리 임포트
if __name__ == '__main__':
onnx_model_path = pass # setting model
tokenizer = pass # setting tokenizer
service = MyBentoService()
service.pack('MyModel', onnx_model_path)
service.pack('tokenizer', {'tokenizer': tokenizer})
saved_path = service.save()
도시락으로 비유해보자면, main.py 를 작성하는 것은 ‘어떤 밥과 반찬들을 어떤 이름의 도시락에 담겠다.’ 하는 내용을 설정해주는 것이라고 생각할 수 있습니다.
service = MyBentoService()- BentoService 클래스의 인스턴스를 생성합니다.
- service 라는 인스턴스명은 당연히 다르게 설정해주어도 됩니다.
- 다만 service 라고 설정해주는 것이 일반적입니다.
service.pack- 앞서 세팅한 model, tokenizer 등 변수들과 BentoService 클래스를 하나의 번들로 패키징합니다.
- 여기서 ‘MyModel’ 즉, 모델명은 BentoService 클래스의 artifact 이름과 일치해야 합니다.
- @bentoml.artifacts([OnnxModelArtifact(‘MyModel’)])
3-2-2. Prediction Service Class
main.py 작성이 완료되었다면, 이름을 설정해주었던 Service Class를 실제로도 생성해주어야 합니다. (클래스명은 예시로 INCClassifier 라고 해보겠습니다.) ‘생성’이라고 했지만 사실상 새로이 작성하는 코드는 몇 줄 되지 않았습니다. 우리가 일반적으로 작성하는 모델의 predict 함수를 bentoml 에서 요구하는 형식에 맞게 정리하고, 몇가지 데코레이터를 추가해주는 작업에 지나지 않았다고 생각합니다.
# Prediction Service Class
# 모델이름or서비스명.py
onnx, onnxruntime, bentoml 등 필요한 라이브러리 임포트
@bentoml.env(infer_pip_packages=True, pip_packages=['onnxruntime-gpu'])
@beotml.artifacts([OnnxModelArtifact('MyModel', backend='onnxruntime-gpu'), PickleArtifact('tokenizer')])
class MyBentoService(bentoml.BentoService):
def __init__(self):
super().__init__()
# setting instance variables
@bentoml.api(pass)
def predict(self, received_data):
sess = self.artifacts.MyModel
tokenizer = self.artifacts.tokenizer.get('tokenizer')
# input data preprocessing
try:
output = pass # inferencing
output = pass # postprocessing
return output
except:
raise error
위에서 main.py 의 내용이 ‘어떤 밥과 반찬들을 어떻게 조합하여 어떤 이름의 도시락에 담겠다.’하는 내용을 설정해주는 것이라고 했습니다. 도시락의 이름이 바로 Service Class의 클래스명에 해당한다고 생각할 수 있습니다. 위 예시에서는 INCClassifier 가 도시락의 이름인 것이죠.
조금 더 쉬운 예로, ‘전주비빔밤’이라는 이름의 Service Class를 만들었다고 가정해봅시다. 그러면 손님(User)이 도시락의 음식을 섭취하기까지는 ‘밥 위에 고추장을 올린다(데이터 전처리) → 나물과 밥과 고추장을 골고루 비빈다(모델 추론) → 한 입만큼의 양을 숟가락 위로 올린다(데이터 후처리)’ 의 과정을 거쳐야 할 텐데요. 바로 그러한 과정이 Service Class의 predict 함수 아래에서 이루어지게 되는 것입니다.
bentoml.env- requirements.txt 파일에 포함되게 될 패키지와 라이브러리들을 인식하는 과정입니다.
- infer_pip_packages=True
- predict 실행에 필요한 패키지와 라이브러리들을 자동으로 인식합니다.
- pip_packages=[‘onnxruntime-gpu’]
- infer_pip_packages=True 로 인식하지 못하는 라이브러리를 따로 명시해줍니다.
bentoml.artifacts- main.py 에서 패키징한 artifacts 의 종류에 따라 다른 Artifact 클래스를 사용합니다.
- 지원하는 artifact 클래스의 종류는 BentoML 공식 깃헙의 해당 경로에서 찾을 수 있습니다.
bentoml.api- input/output data 의 유형, 배치 여부, mb_max_latency, mb_max_batch_size, route, tracer 등 상세 API 스펙을 설정할 수 있습니다.
self.artifacts.MyModel,self.artifacts.tokenizer.get('tokenizer')- main.py 에서 패키징했던 artifact 들을 BentoService Class predict 함수에서 호출하는 방법입니다.
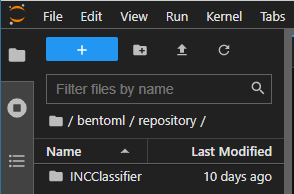
3-2-3. bento bundle 생성 확인
main.py 와 Prediction Service Class 작성 완료 후 main.py 를 실행하면 (경로 변경이 별도로 없었을 경우) 홈경로/bentoml/repository 에 bento bundle 이 생성됩니다.
$ python main.py
3-3. bento bundle → dockerizing
bentoml/repository/서비스클래스명/버전명 으로 들어가보면, Dockerfile + docker-entrypoint.sh + requirements.txt 등 도커라이징을 위한 모든 파일이 이미 생성되어 있는 것을 확인할 수 있습니다.
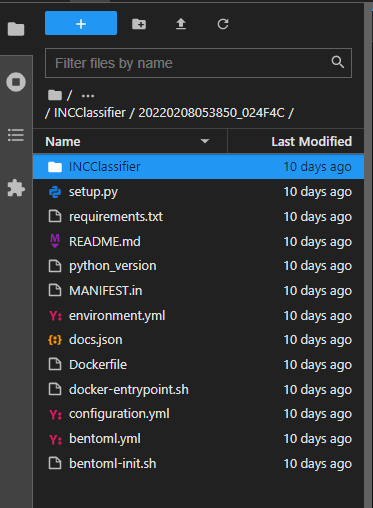
뿐만 아니라, 전 단계에서 Service Class 를 생성할 때 api 데코레이터로 이미 API 객체까지 생성이 완료된 상황입니다. 이제는 BentoML 이 생성해준 파일들을 활용해 터미널 명령어로 이미지를 빌드하고 컨테이너를 띄우기만 하면 됩니다.
만약 API 의 옵션을 수정하고 싶다면 configuration.yml 파일을 작성한 뒤 컨테이너를 실행할 때 컨테이너의 환경변수 BENTOML_CONFIG 에 configuration.yml 파일을 설정해주면 됩니다.
# configuration.yml
bento_server:
workers: 7
timeout: 180
3-4. Building Image & Deploying
아래는 이미지를 빌드하고 컨테이너를 실행하는 코드 예시입니다.
# 이미지 빌드하기
sudo docker build -t <팀명or계정명>/<이미지이름> <Dockerfile경로>
# 컨테이너 실행
sudo docker run -d -v <configuration.yml파일경로>:/home/bentoml/configuration.yml -e BENTOML_CONFIG=/home/bentoml/configuration.yml --net host --runtime nvidia <팀명or계정명>/<이미지이름>
3-4. Jmeter 성능 테스트
BentoML 을 활용해 컨테이너에 띄운 API 의 성능을 JMeter 로 측정해보았습니다.
API 의 옵션은 아래와 같이 workers 를 7로 설정하여 7개의 모델이 병렬로 데이터를 처리할 수 있도록 했고, timeout 발생 기준을 180 초로 넉넉히 설정했습니다.
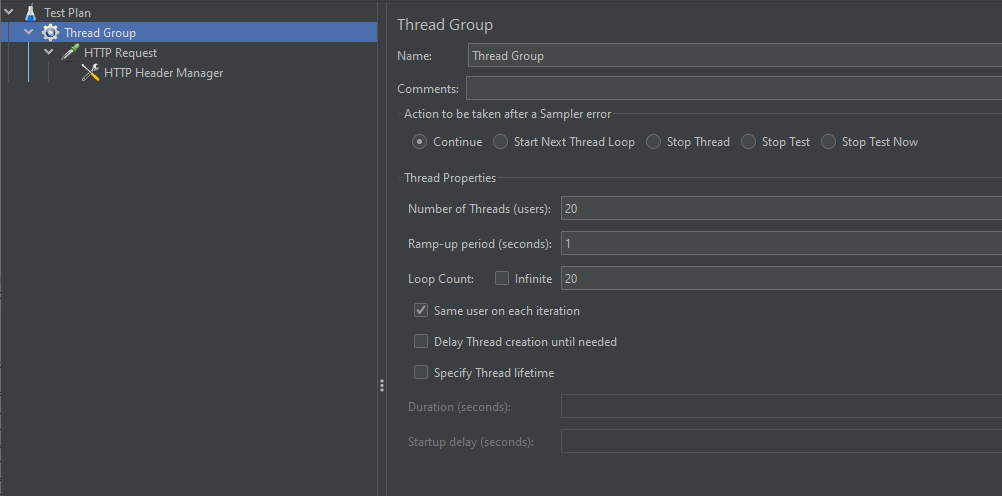
성능 테스트는 동시 접속자(Number of Threads) 를 20명이 1초(Ramp-up period)에 한 번, 이를 20번(Loop Count) 반복하는 조건으로 진행했습니다.
그랬을 때, BentoML 로 서빙한 투자줌 뉴스 카테고리 분류 모델 API 의 성능 테스트 결과 summary 는 아래와 같았습니다.
Creating summariser <summary>
Created the tree successfully using /home/jaylnne/jmeter/fnc_test_4.jmx
Starting standalone test @ Mon Jan 24 16:14:12 KST 2022 (1643008452585)
Waiting for possible Shutdown/StopTestNow/HeapDump/ThreadDump message on port 4445
summary + 37 in 00:00:17 = 2.1/s Avg: 6943 Min: 1073 Max: 9090 Err: 0 (0.00%) Active: 20 Started: 20 Finished: 0
summary + 75 in 00:00:30 = 2.5/s Avg: 8033 Min: 7261 Max: 8703 Err: 0 (0.00%) Active: 20 Started: 20 Finished: 0
summary = 112 in 00:00:47 = 2.4/s Avg: 7673 Min: 1073 Max: 9090 Err: 0 (0.00%)
summary + 74 in 00:00:31 = 2.4/s Avg: 8068 Min: 7530 Max: 8749 Err: 0 (0.00%) Active: 20 Started: 20 Finished: 0
summary = 186 in 00:01:18 = 2.4/s Avg: 7830 Min: 1073 Max: 9090 Err: 0 (0.00%)
summary + 68 in 00:00:30 = 2.3/s Avg: 8840 Min: 8014 Max: 10118 Err: 0 (0.00%) Active: 20 Started: 20 Finished: 0
summary = 254 in 00:01:47 = 2.4/s Avg: 8100 Min: 1073 Max: 10118 Err: 0 (0.00%)
summary + 73 in 00:00:30 = 2.4/s Avg: 8182 Min: 7362 Max: 8955 Err: 0 (0.00%) Active: 20 Started: 20 Finished: 0
summary = 327 in 00:02:17 = 2.4/s Avg: 8119 Min: 1073 Max: 10118 Err: 0 (0.00%)
summary + 69 in 00:00:30 = 2.3/s Avg: 8701 Min: 7558 Max: 10269 Err: 0 (0.00%) Active: 5 Started: 20 Finished: 15
summary = 396 in 00:02:47 = 2.4/s Avg: 8220 Min: 1073 Max: 10269 Err: 0 (0.00%)
summary + 4 in 00:00:02 = 2.6/s Avg: 8003 Min: 7796 Max: 8365 Err: 0 (0.00%) Active: 0 Started: 20 Finished: 20
summary = 400 in 00:02:49 = 2.4/s Avg: 8218 Min: 1073 Max: 10269 Err: 0 (0.00%)
Tidying up ... @ Mon Jan 24 16:17:01 KST 2022 (1643008621514)
... end of run
BentoML 공식에서는 Adaptive Micro Batching 메커니즘을 활용함으로써 Flask 기반 API 보다 최대 100배에 달하는 처리량을 보인다고 말하고 있었습니다. 그리고 비교를 위해 flask 로 띄워본 투자줌 뉴스 카테고리 분류 API 보다 BentoML 로 서빙한 API가 약 수십 배 더 높은 성능을 보이는 것을 실제로 확인했습니다.
3-5. Swagger UI Test
글 초반에 언급했던 것처럼 BentoML 은 별다른 추가 작업이나 설정 없이도 API 의 Swagger UI 를 제공합니다. (투자줌 뉴스 카테고리 분류 API 를 현재 잠시 내려둔 상태이기 때문에 아래 이미지 예시는 뉴스 요약 모델의 Swagger UI 를 가져왔습니다. 서비스명 외 모든 부분이 같습니다.)
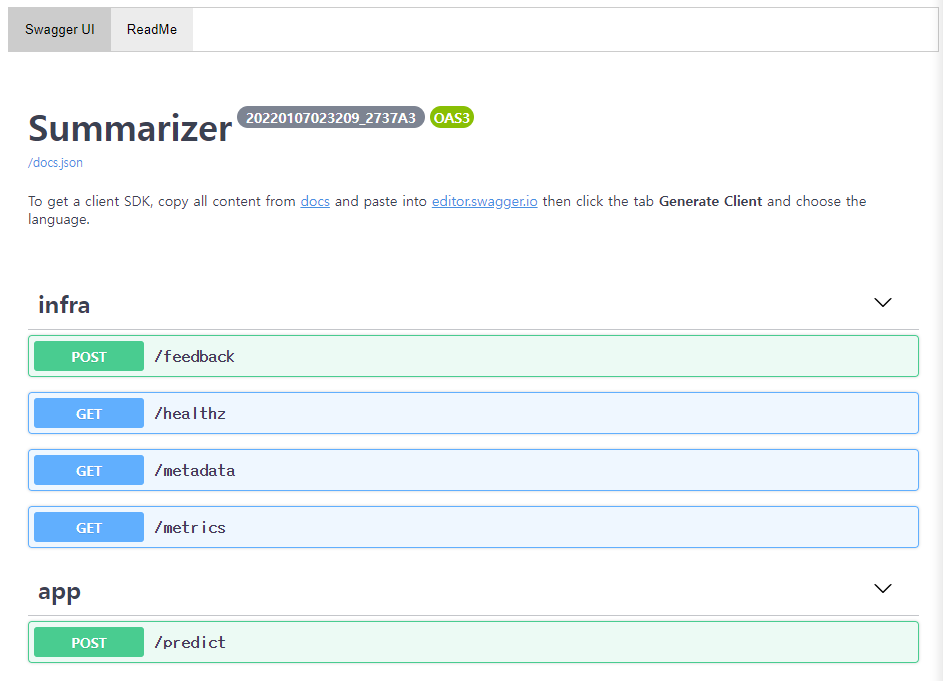
app 의 /predict 경로에서 ‘Try it out’ 을 통해 내가 개발한 모델의 api app 을 테스트할 수 있습니다.
.png)
4. 느낀 점
장점
- 개발 시간이 단축된다는 점이 가장 확연하게 느껴지는 장점이었습니다. 모델을 개발하는 작업과 달리 모델을 도커라이징하고 또 배포하는 과정은 다소 반복적인 면이 있는데, 이를 몇 줄 코드만으로 해결할 수 있기 때문에 전체적인 작업 효율성이 매우 높아진 것 같습니다.
-
글 초반에 언급했던 것처럼, 별다른 추가 작업이나 설정 없이도 Swagger UI 를 호스팅합니다. Prediction Servica Class 위에 @web_static_content 데코레이터를 추가하면 편리하게 웹 프론트엔드 프로젝트도 함께 번들링(bundle)할 수 있다고 합니다.
# 공식 GitHub 예시 코드 @env(auto_pip_dependencies=True) @artifacts([SklearnModelArtifact('model')]) @web_static_content('./static') class IrisClassifier(BentoService): @api(input=DataframeInput(), batch=True) def predict(self, df): return self.artifacts.model.predict(df) -
BentoML 로 패키징한 bento bundle 은 Yatai(야타이) 와 연동하여 버전 관리를 할 수 있습니다. Yatai 란 Model Management Component 로 ‘포장마차’ 라는 의미를 가진 일본어 입니다. Bento(벤또, 도시락) 을 판매하는 포장마차를 생각하면 이해가 쉬운 것 같습니다. 보통 DL 모델의 weight 파일은 용량이 너무 커서 Github 이나 Gitlab 레포지토리로 관리할 수가 없어 weight 파일만을 따로 저장 서버에 두고 관리하여야 하는데, Yatai 는 그러한 단점이 없이 패키징한 bento bundle 을 그 자체로 저장소에 push, pull, retrieve, delete 할 수 있어 매우 편리해보입니다.
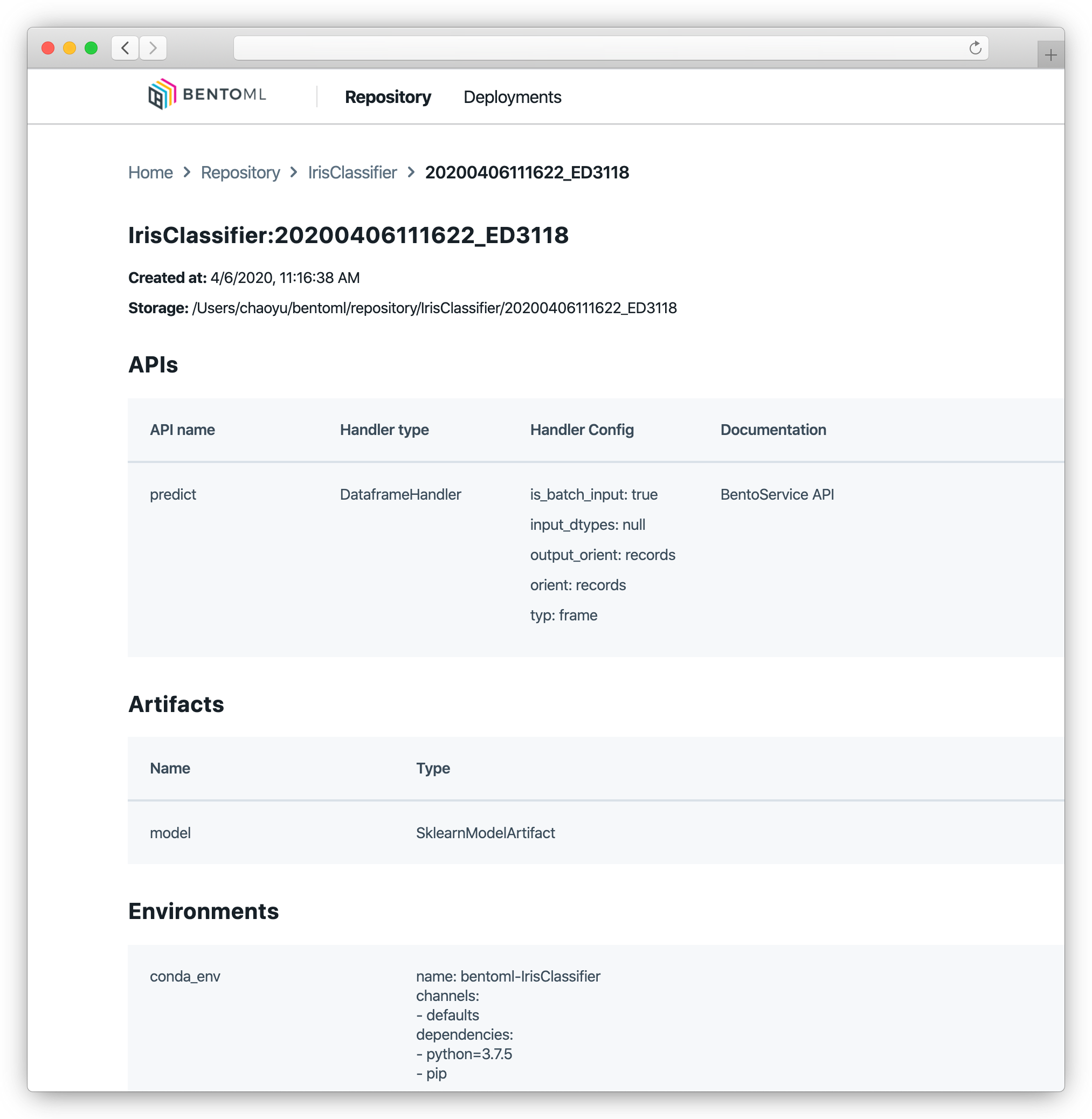 이미지 출처: BentoML documentation
이미지 출처: BentoML documentation -
BentoML 은 거의 모든 메이져 머신러닝 프레임워크와 라이브러리를 지원합니다. 때문에 BentoML 을 활용하기 위해 모델링 단계에서 프레임워크나 라이브러리 사용에 제약을 받을 만한 사항은 거의 없을 것으로 생각됩니다.
, BentoML](/images/lab/post/2022-02-21-BentoML/bentoml.png) 이미지 출처: sooftware.io, BentoML
이미지 출처: sooftware.io, BentoML - 타 MLOps 툴과 연동하여 사용할 수도 있습니다. 대표적인 예로, MLflow + BentoML 의 조합을 들 수 있습니다. BentoML 이 yatai 와의 연동을 공식적으로 지원하긴 하지만, 모델 버전과 배포 관리에 있어서는 MLflow 가 더 많은 기능을 갖추고 있으며 더 큰 사용자 커뮤니티를 형성하고 있습니다. 때문에 BentoML 을 이용하여 모델을 패키징 및 도커라이징하고, MLflow 를 통해 패키징된 모델의 버전을 관리, 배포 및 모니터링하는 조합이 많이 사용되고 있는 것 같습니다.
단점
- 아직은 완벽히 성숙한 단계라고 보기 어려울 것 같습니다. 2019년부터 개발이 시작된 프로젝트이며 최근 굉장히 가파른 속도로 커뮤니티가 성장하고 있는 라이브러리이긴 하지만 아직까지도 성숙해가는 단계에 있다고 생각됩니다.
- pytorch lightning 으로 개발한 모델의 패키징을 지원하고 있다고 하지만 이번 저의 경우에는 결국 onnx 로 exporting 한 이후의 모델을 패키징할 수 있었습니다. (모든 pytorch lightning 모델에 발생하는 문제는 아닙니다.) 관련된 이슈가 커뮤니티에서 논의되고 있는 것을 보아 언젠가 문제가 해결된 버전이 출시되지 않을까 싶습니다.
-
configuration.yml 에 설정한 timeout 옵션만이 작동합니다. Dockerfile 마지막 CMD 에서 workers 와 timeout 을 설정하는 방법을 가장 먼저 시도하였지만, workers 는 옵션값을 잘 인식하는 반면, timeout 은 이런저런 해결책을 아무리 시도해보아도 설정값이 인식되지 않았고, 결국 configuration.yml 을 통한 설정만이 작동했습니다.
 Dockefile 내 API 실행 명령어 라인에서의 timeout 옵션이 작동하지 않음.
Dockefile 내 API 실행 명령어 라인에서의 timeout 옵션이 작동하지 않음.
5. 맺으며
구글에서 발표한 논문 중 ‘Hidden Technical Debt in Machine Learning Systems (머신러닝 시스템에서 발생할 수 있는 기술 부채에 대한 이야기)’ 에 삽입되어, MLOps 와 관련한 아티클에 자주 인용되는 이미지가 있습니다.
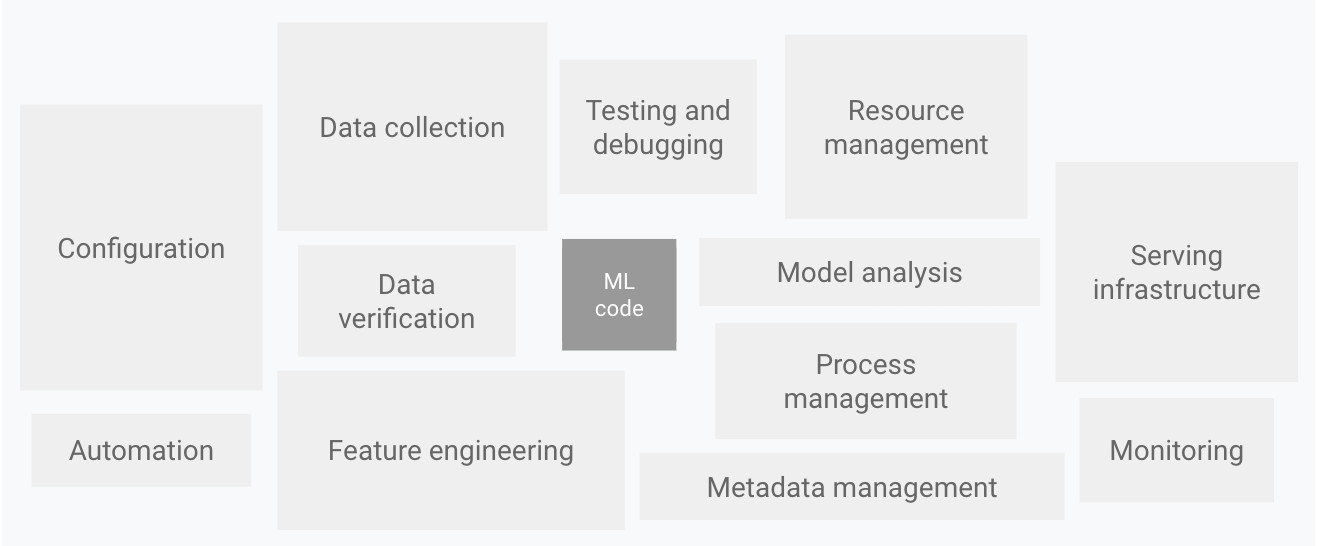
이처럼, 머신러닝 모델을 서비스하기 위해서는 모델을 개발하는 것 외에 복잡하고 광범위한 주변 기술이 추가적으로 필요합니다. 이러한 문제를 해결하기 위해 DevOps 방법론을 ML 에 적용한 것이 MLOps 인데, 최근 MLOps 는 춘추전국시대라고 불릴 만큼 많은 툴들이 개발되어 각각 빠른 속도로 성장하고 있습니다. 연구적 목적으로 많이 개발되어왔던 인공지능이 이제는 활발하고 광범위하게 실서비스에 적용되기 시작한 것이 원인이라고 생각합니다.
하루가 다르게 새로운 것이 생겨나면서 유독 빠르게 변화하고 있는 분야이기 때문에, 앞으로도 계속해서 이 분야의 트렌드를 살피며 공부하여 새로운 기술에 대한 적응력을 높여야겠다고 생각하게 되었습니다. 그리고 그렇게 함으로써, 함께 일하는 줌인터넷 데이터 사이언티스트 동료들이 이러한 기술들을 너무 어렵지 않게 접할 수 있도록 길잡이 역할을 할 수 있었으면 합니다! ✨
그럼, 지금까지 긴 글 읽어주셔서 감사합니다.
 Thank you!
Thank you!

Comments