17 min to read
AWS DynamoDB 모델링
DynamoDB를 소개하며 RDBMS ERD기반 설계에서 DynamoDB로 Reverse Modeling하는 방법을 공유합니다.
![]()
1. DynamoDB 도입 배경
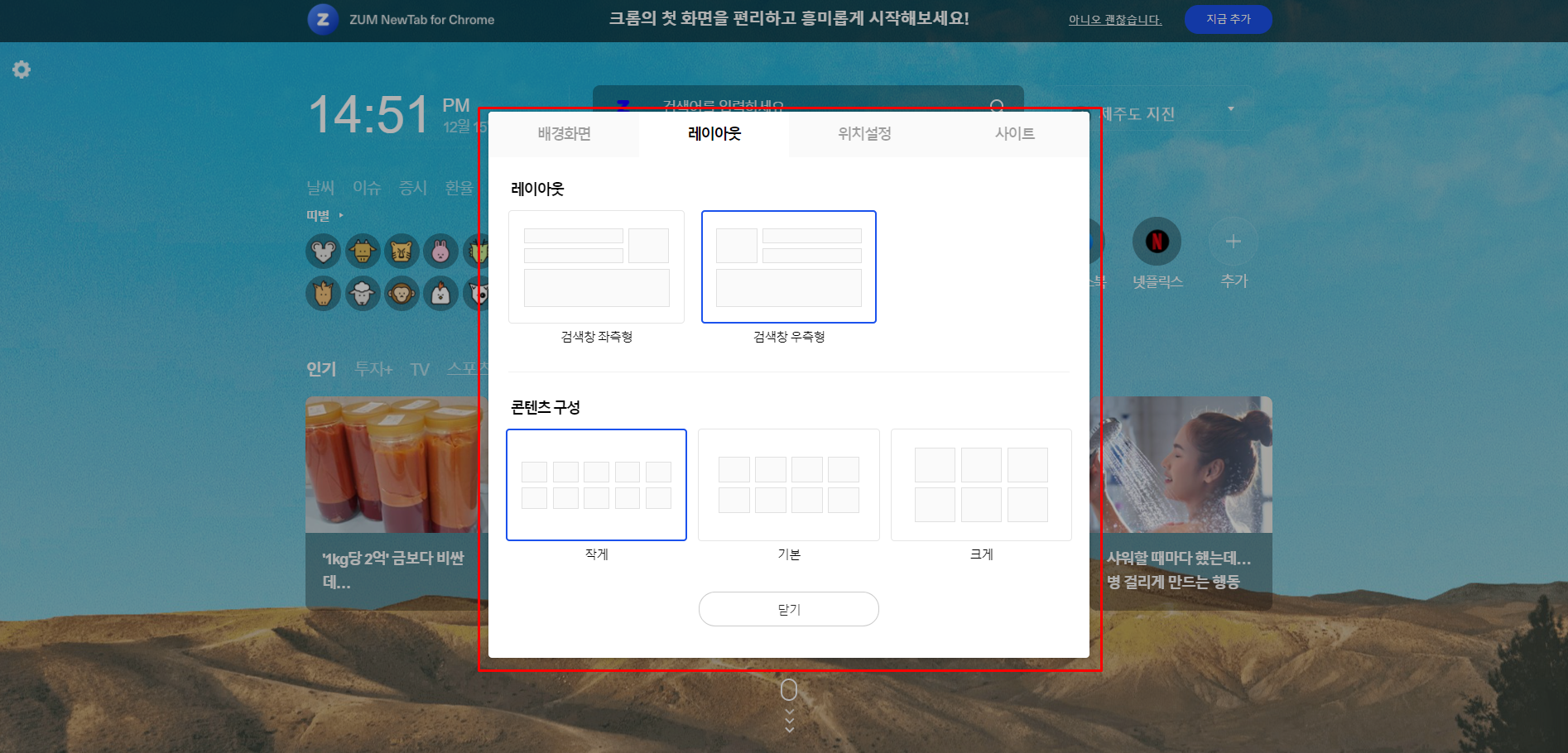
현재 스타트줌(https://start.zum.com/)에서 개인 별 배경화면 / 레이아웃 / 위치설정 / 사이트 바로가기를 설정할 수 있습니다.
해당 데이터들은 브라우저 로컬 스토리지에 저장되어서 페이지가 렌더링 될 때 로컬 스토리지의 데이터를 읽어서 렌더링하고 있습니다. 그렇기 때문에 타PC나 다른 기기로 접속할 경우 개인화 데이터를 재설정해야한다는 불편함이 있습니다.
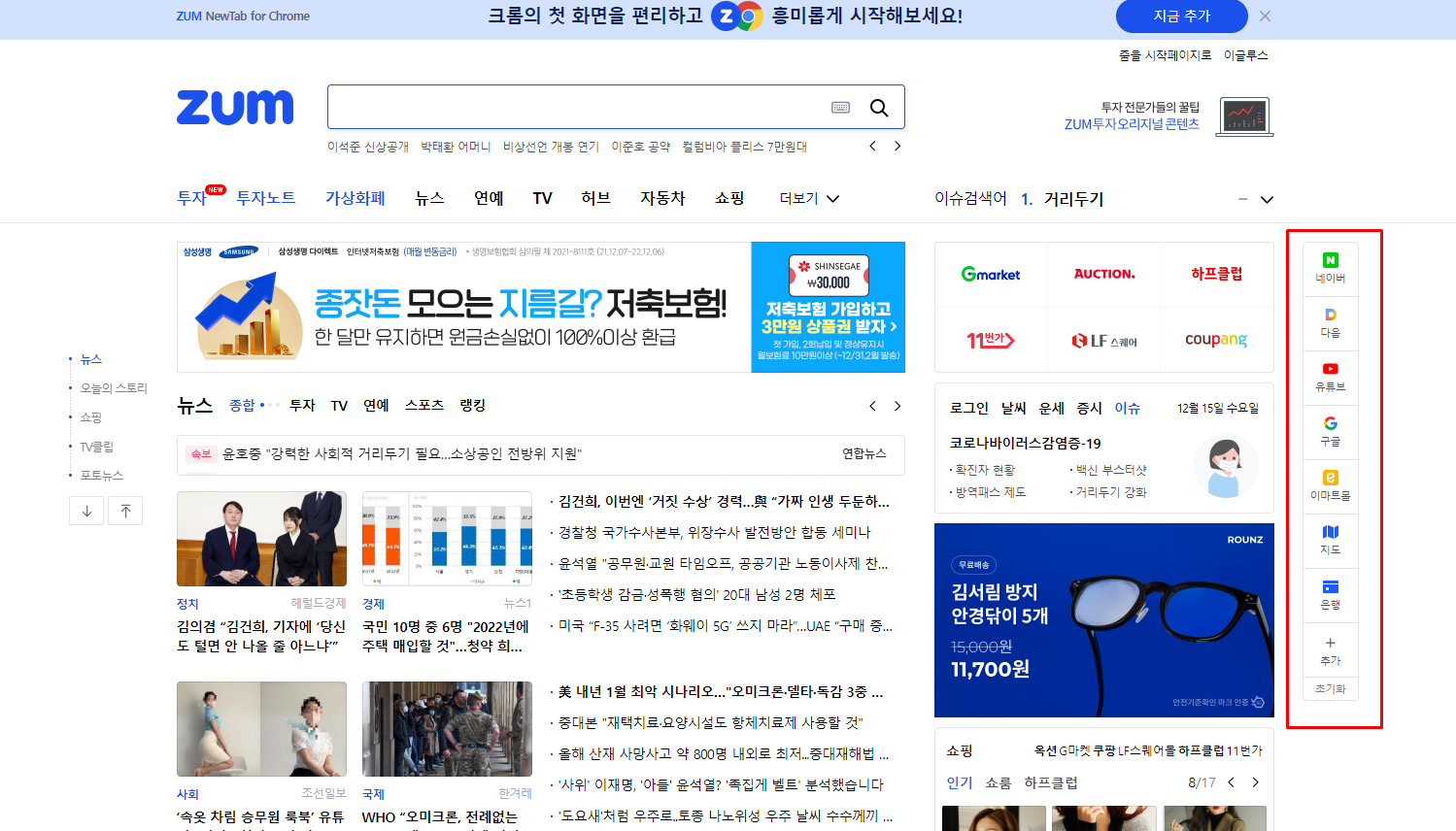
줌은 개방형 포털이라는 슬로건을 가지고 있는 플랫폼이기 때문에 줌을 통해서 다양한 컨텐츠가 제휴될 수 있고 연결 시켜주는 특징이 있습니다.
그렇기 때문에 현재 줌닷컴(https://zum.com/)에 우측 항목을 보면 네이버, 다음, 유튜브, 구글 등 다양한 컨텐츠들로 이동하는 바로가기 목록들을 확인할 수 있습니다.
현재 바로가기 목록에 대한 개인화 데이터들은 사내 IDC에 적재되어 있는데, 줌닷컴은 AWS에 올려져있기 때문에 네트워크 속도 이슈가 있었습니다. (현재는 전용선을 연결하여 개선된 모습입니다.)
현재 서비스하고 있는 뉴스줌, 금융줌, 허브줌, 줌모바일, 스타트줌 등 다양한 서비스 환경에서 각기 다른 개인화 데이터를
DynamoDB에 적재함으로써, 기획에 따라 자주 바뀌는 설정 정보를 RDBMS보다 유연하게 대응할 수 있고, 서비스 운영 측면에서 유지보수와 확장성, 속도 개선등 다양한 이점을 가져갈 수 있습니다.
2. 왜 DynamoDB를 써야하지?
![]()
DynamoDB란?
AWS 공식 홈페이지에 따르면 DynamoDB는 모든 규모에서 10밀리초 미만의 성능을 제공하는 빠르고 유연한 NoSQL 데이터베이스 서비스 라고 소개하고 있습니다.
공식 홈페이지의 소개처럼 DynamoDB는 볼륨이 방대하게 커지더라도 빠르고 일관된 응답시간을 자랑합니다. 이 이유는 DynamoDB가 테이블마다 Primary Key로 Partition Key를 가지고 있는데, Partition Key 때문에 응답시간이 일관됩니다. 이 부분은 뒤에서 다시 설명해드리겠습니다!
DynamoDB 특징
- Fully managed Service
- DynamoDB는 Nosql의 MongoDB와 비교가 많이 되고 있는데, 개인적으로 가장 큰 차이점은
DynamoDB는 Fully managed라는 점인 것 같습니다. 둘 다 대용량 데이터에 굉장히 능한 데이터베이스이지만 MongoDB는 꾸준한 유지/관리가 필요하기 때문에 회사 입장에선 개발자 리소스를 꾸준하게 사용할 수밖에 없습니다. 하지만 DynamoDB는 AWS가 제공하는 Serverless NoSQL이기 때문에NoSQL 엔지니어가 없어도 대용량 트래픽 처리 가능한 어플리케이션을 개발할 수 있고개발자 리소스를 꾸준히 사용하지 않아도 된다는 이점이 있습니다. - 각 기업의 사업이 확장되면서 글로벌 비즈니스를 시작하는 기업들을 위해 글로벌 테이블을 제공합니다.
손쉽게 다른 Region으로 테이블을 복제할 수 있습니다. - DynamoDB는
테이블 크기와 관계 없이 몇 초안에 백업을 완료합니다. 또한 모든 백업은 자동으로 암호화되며, 손쉽게 검색 가능하며 명시적으로 삭제될 때까지 보존합니다. 또한 특정시점복구(PITR)이라는 기능을 활성화 하면 사용자가 명시적으로 비활성화 할 때까지최근 35일 중 원하는 시점으로 테이블 복원이 가능합니다.
- DynamoDB는 Nosql의 MongoDB와 비교가 많이 되고 있는데, 개인적으로 가장 큰 차이점은
- Auto-Scaling 기능 탑재
- DynamoDB로 들어오는 워크로드에 따라서 처리량(RCU / WCU)을 Auto-Scaling 지원합니다.
- DynamoDB 과금 방식으로는
사용한 읽기/쓰기 처리량대로 납부하는 온디맨드 방식과읽기/쓰기 처리량을 미리 할당하는 방식인 프로비저닝 방식이 있습니다. 프로비저닝 방식을 사용할 때, 읽기/쓰기 처리량을 사용하지 않아도 그 금액만큼 과금을 해야하는데 Auto-Scaling을 활용하면유휴 처리량을 절약하여 사용한 만큼만 과금하기 때문에 과금 상 이점을 얻을 수 있습니다.
- 데이터 자동 복제
- DynamoDB는 기본적으로
1개의 Region에 3개의 복제본을 만들어 놓기 때문에 한 곳에서 장애가 나더라도 가용성을 유지할 수 있는 특징이 있습니다.
- DynamoDB는 기본적으로
- High Performance
빠르고 일관된 응답시간(Single-digit millisecond latency)제공하고 있으며, 사실상무제한 쓰로틀링과 무제한 저장 용량을 가지고 있습니다.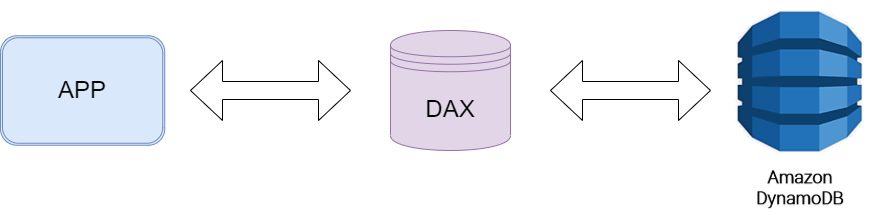
- DAX (DynamoDB Accelerator)
- DynamoDB를 위한 가용성이 뛰어난 완전 관리형인 메모리 캐시로써, 초당 수 백만 개의 요청에서도 DynamoDB 테이블의 읽기 속도를 최대 10배까지 가속화할 수 있습니다.
- 캐싱 서비스(DAX)지원을 통해서
DynamoDB 비용을 절감하고 어플리케이션 처리하는 캐싱로직을 제거함으로써 데이터 일치와 복잡도 감소할 수 있습니다.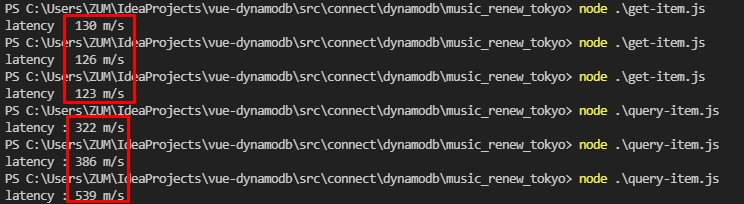
- DAX 사용의 큰 문제점은
현재 서울 Region에서 지원하지 않는다는 점입니다. DAX를 사용하려면 가장 가까운 Region인 도쿄에 DynamoDB를 두는 것인데요. 도쿄에 DynamoDB를 세팅하고 Latency를 측정해본 결과1개의 item을 가져올 땐 120 ~ 130m/s, 1000개의 item을 가져올 땐 300 ~ 500m/s가 측정된 것을 확인할 수 있습니다. 위와 같은 Latency로현재 서버를 서울에 두고 서비스하기엔 무리가 있기 때문에 추후에 서울 Region을 지원할 때 도입하는 것을 권유드립니다.
- 비동기 처리
- NativeCloud 컨셉에 맞게 최소한 인스턴스 Spec으로 자원 효율성을 얻는
Reactive Programming 지원합니다. (https기반 Non-blocking / spring webflux, nodejs)
- NativeCloud 컨셉에 맞게 최소한 인스턴스 Spec으로 자원 효율성을 얻는
DynamoDB Latency
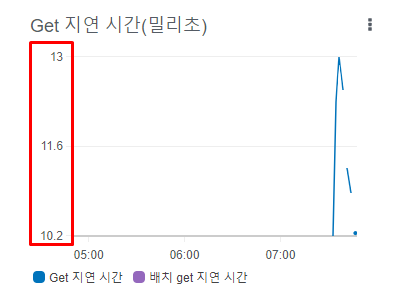
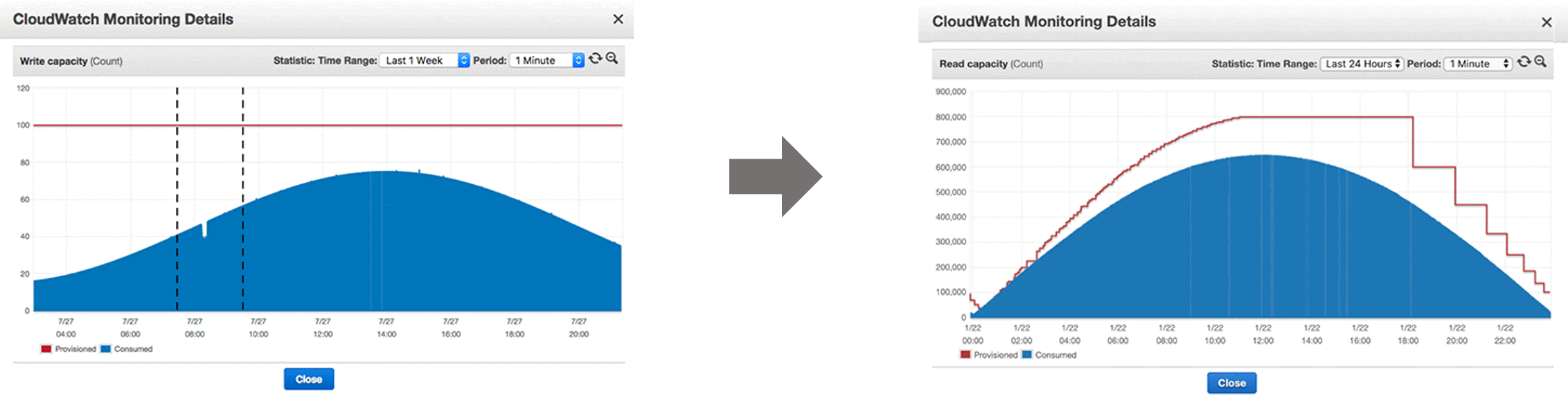
위 그래프는 AWS DynamoDB 테이블에 데이터를 넣고 getItem으로 데이터를 조회한 Latency입니다. CloudWatch 지표이기 때문에 DynamoDB의 순수 Latency를 확인할 수 있습니다. AWS에서 소개한대로 약 10m/s의 응답시간을 확인할 수 있습니다.
하지만! 우리는 어플리케이션에서 접근하기 때문에 순수 Latency+ 네트워크 Latency를 측정해야합니다.
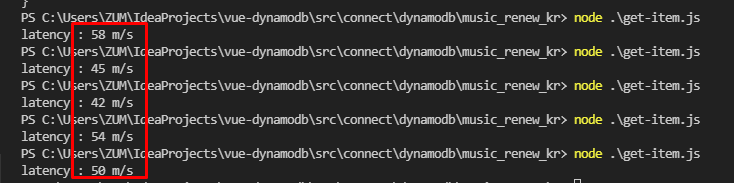
이번엔 로컬환경에서 AWS DynamoDB에 접근하고 측정한 Latency입니다.
어플리케이션에서 측정했기 때문에 순수 Latency가 아닌 네트워크 Latency + 순수 Latency 로 측정했기 때문에 이번에는 약 50m/s의 응답시간을 확인할 수 있었습니다. Latency는 약 50m/s 이지만 DynamoDB 특성상 데이터가 수천만, 수억건이 들어가도 동일한 속도를 보장합니다. 특히, DynamoDB와 어플리케이션 서버 Region이 다르다면 구축하시기 전에 꼭 Latency 먼저 측정하시는 걸 권유 드립니다!
3. DynamoDB 구성
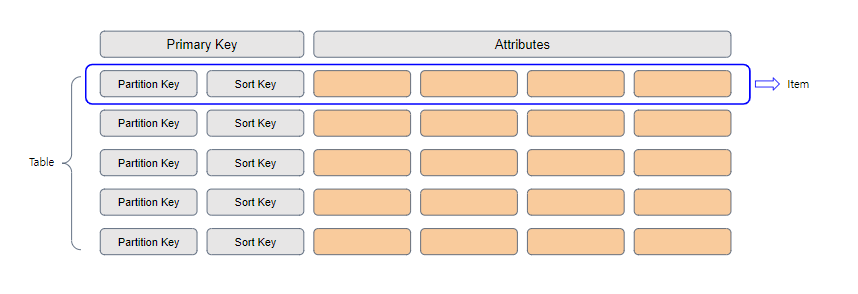
DynamoDB는 기본적으로 Schemaless 테이블이며, Primary Key로는 파티션 키(Partition Key)와 정렬키(Sort Key)를 가지고 있으며 그 외 속성들인 Attributes로 구성되어 있습니다.
RDBMS에선 데이터 한 줄을 row라고 읽었다면 DynamoDB에선 item이라고 표현합니다.
Primary Key
-
파티션 키(Partition Key)
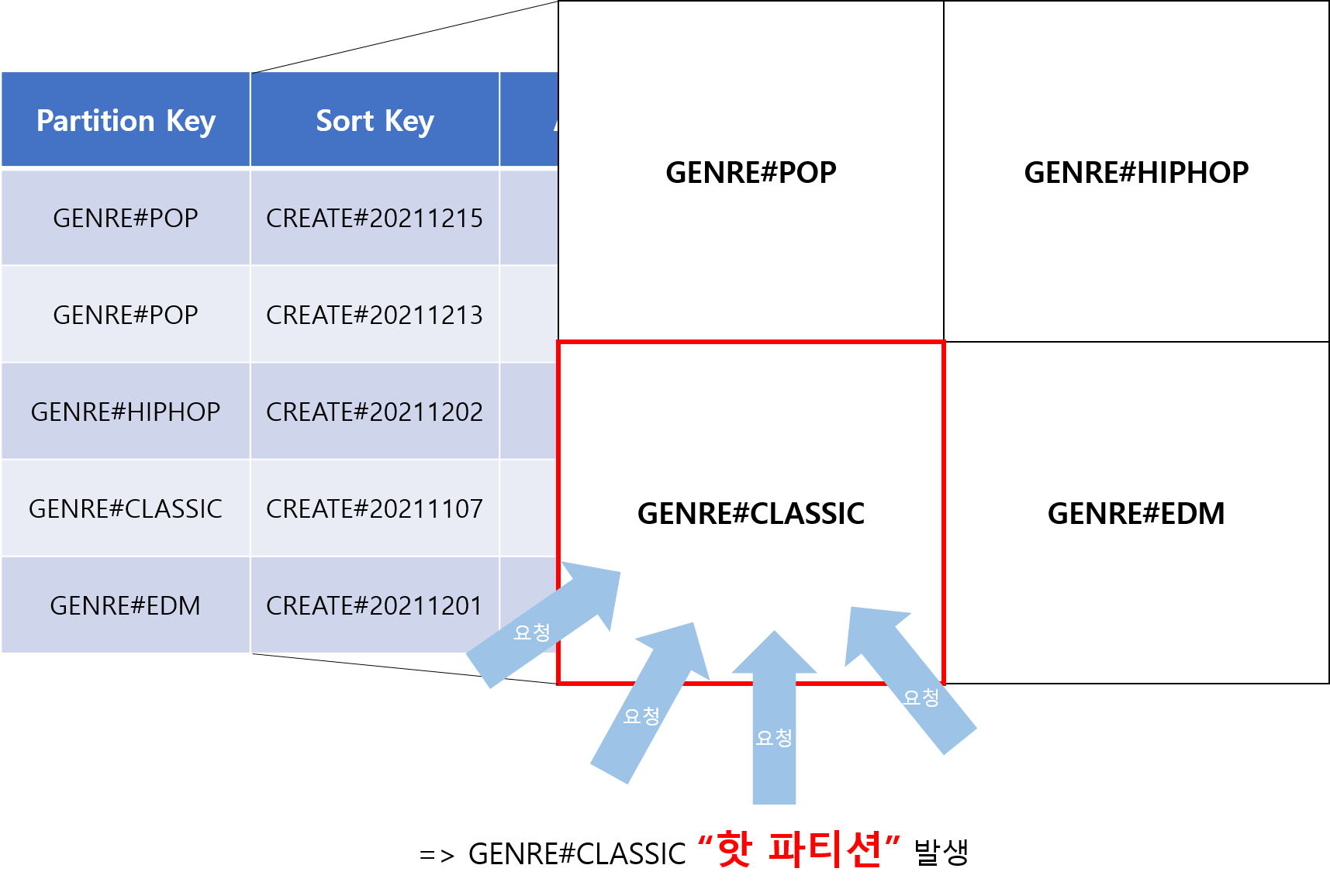
파티션 키는 Primary키로써 테이블 생성 시 필수 입력 사항이며, 파티션 키 수만큼 DynamoDB를 파티셔닝해서 들어오는 데이터를
각 파티션에 나눠서 적재하게 됩니다.위 테이블은 장르 별로 파티션 키를 나누었습니다. 장르 같은 경우에는 카디널리티가 낮기 때문에 각 파티션에 많은 데이터들이 적재하게 됩니다. 위 그림과 같이 클래식이라는 장르에 많은 요청이 몰리게 된다면
"핫 파티션"이 발생하여 모든 파티션에 읽기/쓰기 성능에 영향을 주게 됩니다. 그렇기 때문에 파티션 키는카디널리티가 높은 속성으로 지정하고데이터가 파티션 고르게 분산하도록 설계하는 것이 좋습니다. (ex. 고객ID, 물품ID 등)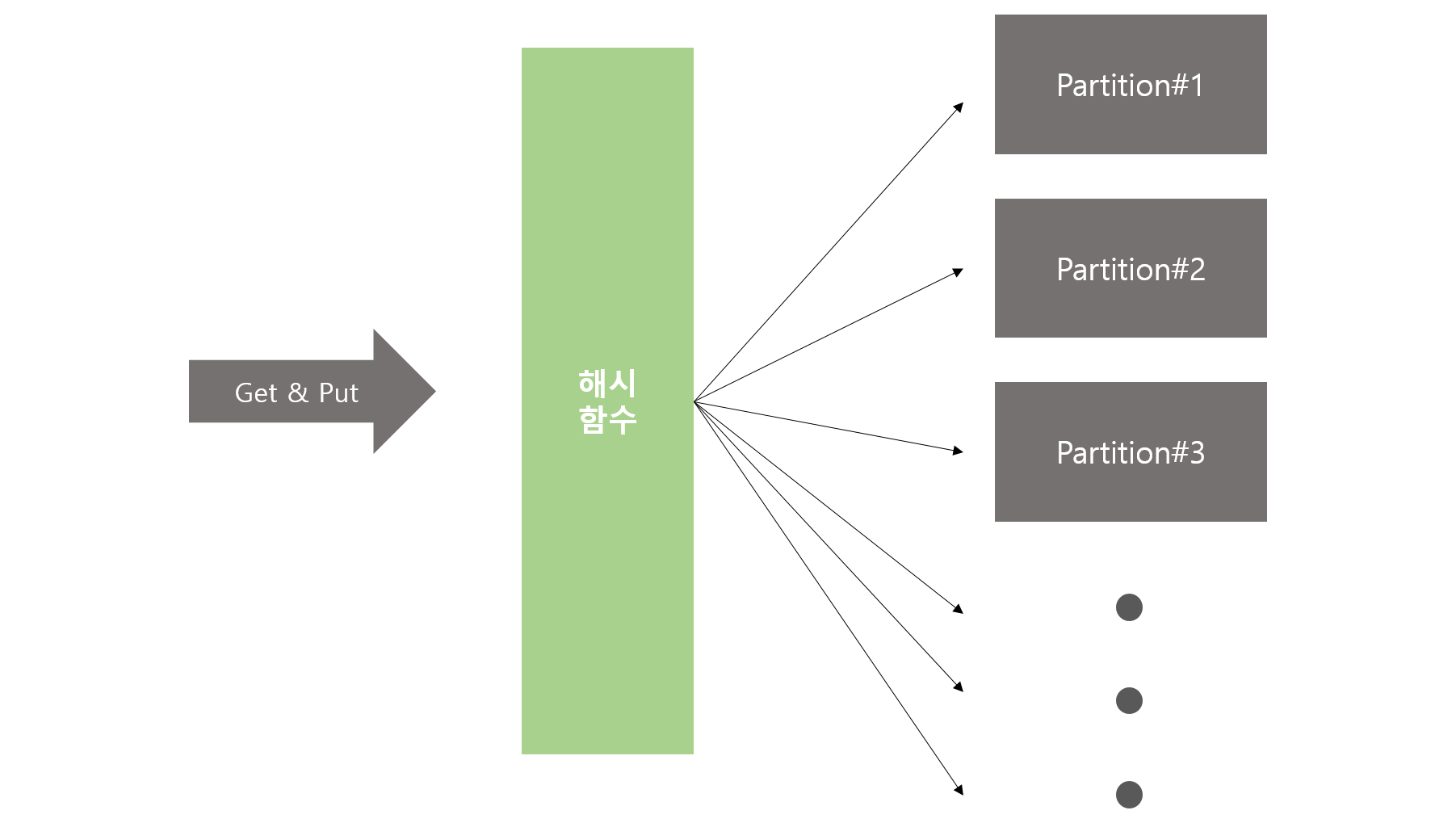
DynamoDB는 테이블 볼륨이 방대해지더라도 항상 일관된 응답시간을 제공해준다고 위에서 말씀드렸습니다. 그 이유는
파티션 키 내부에 해시 함수를 가지고 있기 때문에요청 받은 파티션 키를 파라미터로 Hash Value를 도출하여 파티션이 결정되기 때문입니다. 그래서 테이블이 아무리 커지더라도파티션 키를 인자로 Hash Value를 도출하여 빠른 속도로 해당 데이터에 접근하기 때문에 일관된 응답 시간을 제공할 수 있습니다.파티션 키 연산은 “Equal” 연산만 가능합니다
-
정렬키(Sort Key)
정렬키는 Primary Key이지만 테이블 생성 시 선택 입력 사항입니다. 주로 선택적, 범위 조회를 위해 사용하며, 관계 모델링에서 1:n관계와 n:m 관계를 모델링할 수 있습니다.
정렬 키를 사용하여 데이터를 적재하는 모범 사례

위 그림은 AWS 공식 문서에서 권유하는 정렬 키 모범 사례입니다. 정렬 키로
선택/범위 연산이 가능하기 때문에 데이터를 계층적으로 설계하여 해당 계층에 맞는 데이터를 가져올 수 있습니다. 이렇게 적용하면 지리적 위치를 큰 범위부터 작은 범위로 계층적으로 나열하기 때문에country부터 neighborhood까지의 데이터를 효과적으로 범위 쿼리할 수 있게됩니다.정렬키는 선택, 범위 연산인 >,>=,<,<=,begin_withs,between 연산이 가능합니다
Index
DynamoDB는 Real World에서 데이터를 접근하기에 Primary Key(PK + SK)만으로는 부족하기 때문에 보조 인덱스(Secondary Index)를 추가적으로 제공합니다. 보조 인덱스는 LSI (Local Secondary Index)와 GSI(Global Secondary Index) 두 가지로 나뉘어집니다.
-
LSI (Local Secondary Index)
- 테이블과 동일한 Partition Key를 사용하며, Sort Key 지정
- 테이블 생성 시에만 생성 가능하며, 삭제 불가능
- 용량은
10GB로 제한 - 파티션 내 테이블 데이터와 함께 저장
- 테이블의 RCU / WCU 같이 사용
- Eventual Consistent Read와 Strong Consistent Read 선택 가능
- LSI 사용은
최대한 지양
⇒ 이유?
LSI는 파티션 키를 테이블의 파티션 키와 동일하게 설정해야하기 때문에 두 파티션 키가 같은 데이터를 바라보고 연산한다는 점에서 메리트가 떨어지고, 특히나 용량 제한이 있어서 테이블 볼륨이 늘어날수록 해야하며 추가적인 생성과 삭제가 불가능하기 때문입니다.
-
GSI (Global Secondary Index)
- Partition Key를 필수 설정하고, Sort Key는 선택 사항
- 테이블 생성 후에도
생성/삭제 가능 - 용량
제한 없음 - 테이블 외 인덱스 데이터 따로 저장
- 테이블 외 인덱스에서 RCU / WCU 따로 사용
- Eventual consistent read만 가능
- GSI 사용 권장
인덱스에 대한 내용을 읽으시면서 ‘아 두 가지 인덱스가 존재하고 LSI 사용을 지양하고 최대한 GSI로 인덱스를 구성해야겠구나’를 느끼셨을 것 같습니다. 하지만 읽다보니 ‘Eventual Consistent Read와 Strong Consistent Read를 선택하고 사용 가능하다는데 이게 뭐지?’ 라고 생각이 드셨을 것 같습니다. Eventual Consistent Read와 Strong Consistent Read는 데이터베이스에서 데이터를 어떤 일관성으로 가져올 것이냐? 하는 읽기 일관성을 나타냅니다.
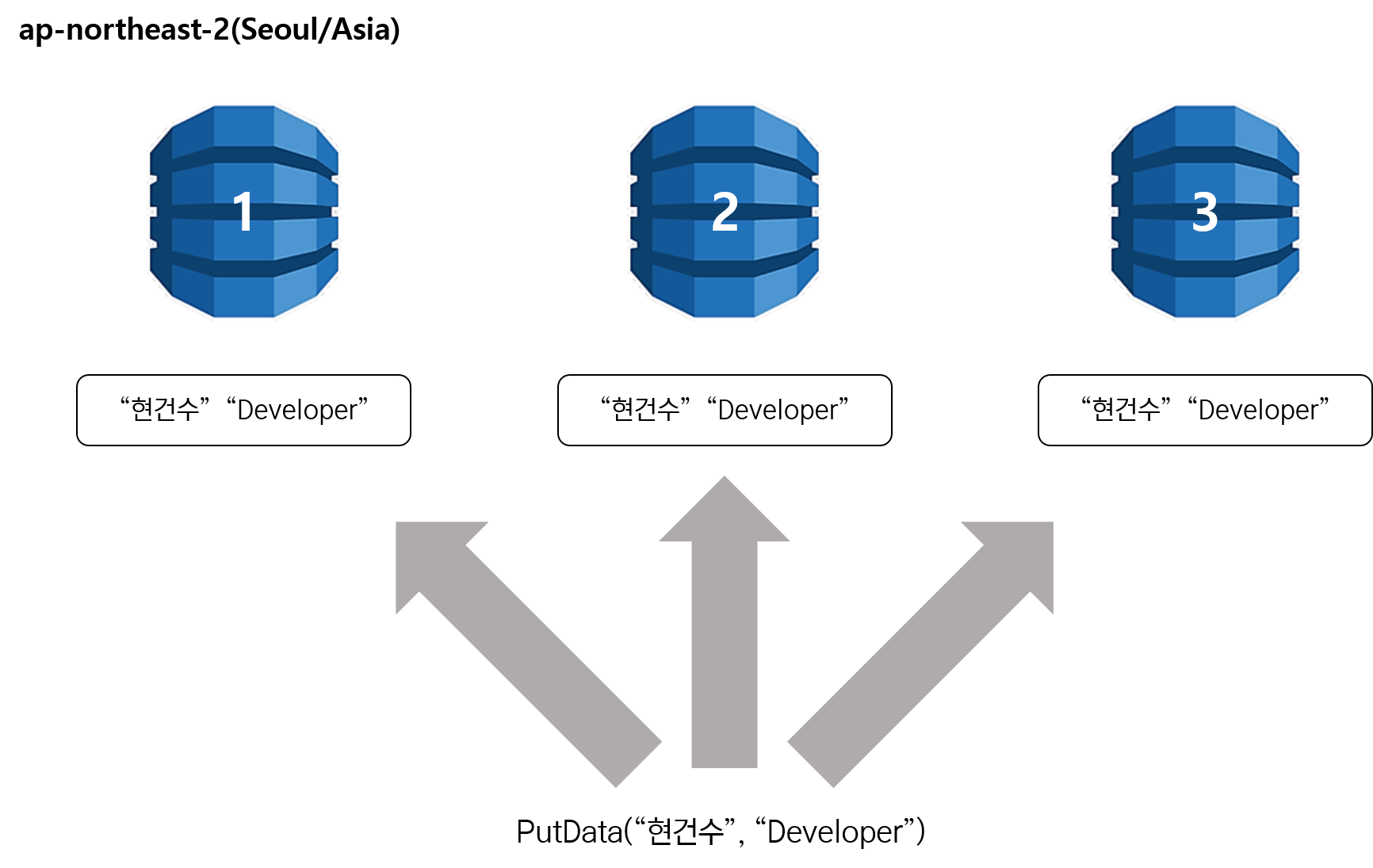
Eventual Consistent Read
위에서 DynamoDB는 한 Region 당 3개의 복제본을 가지고 있다고 설명 드렸습니다. 이 복제본들에 데이터가 삽입되고 수정될 경우에 3개의 복제본들은 짧은 시간 안에 같은 데이터가 삽입되고 수정되면서 동기화 된다고 생각하시면 될 것 같습니다.
Eventual Consistent Read는 3개의 복제본 DynamoDB 중에 네트워크 응답 시간이 가장 빠른 DynamoDB를 선택해서 데이터를 가져오게 됩니다.
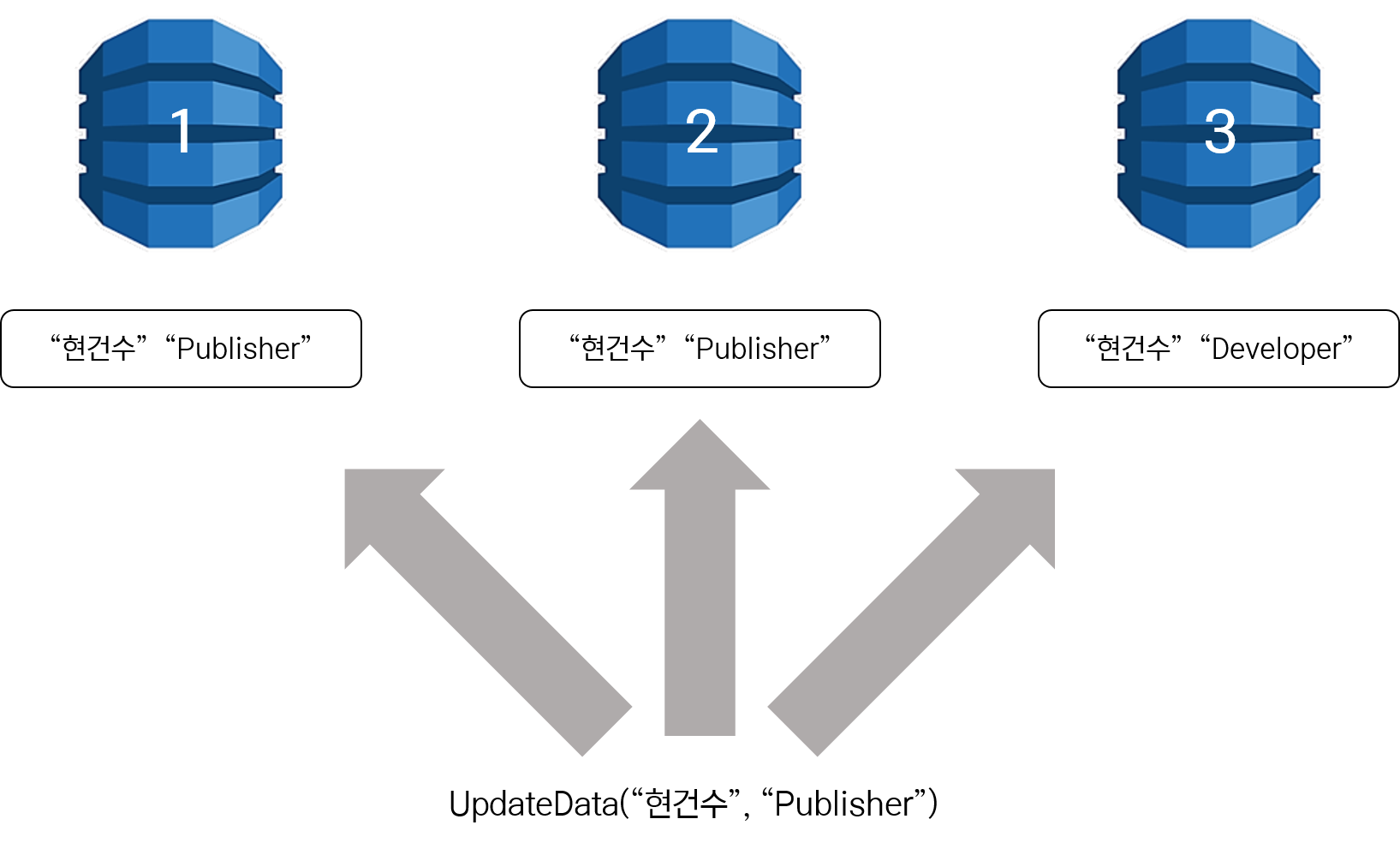
위 그림은 “현건수”라는 데이터를 “Publisher”로 업데이트를 해줘! 라는 요청을 보내서 1번,2번 DB는 업데이트가 되었고 3번 DB는 아직 “현건수”라는 데이터가 “Developer”를 가지고 있습니다.
이 상황에서 데이터를 조회한다면 어떻게 될까요?
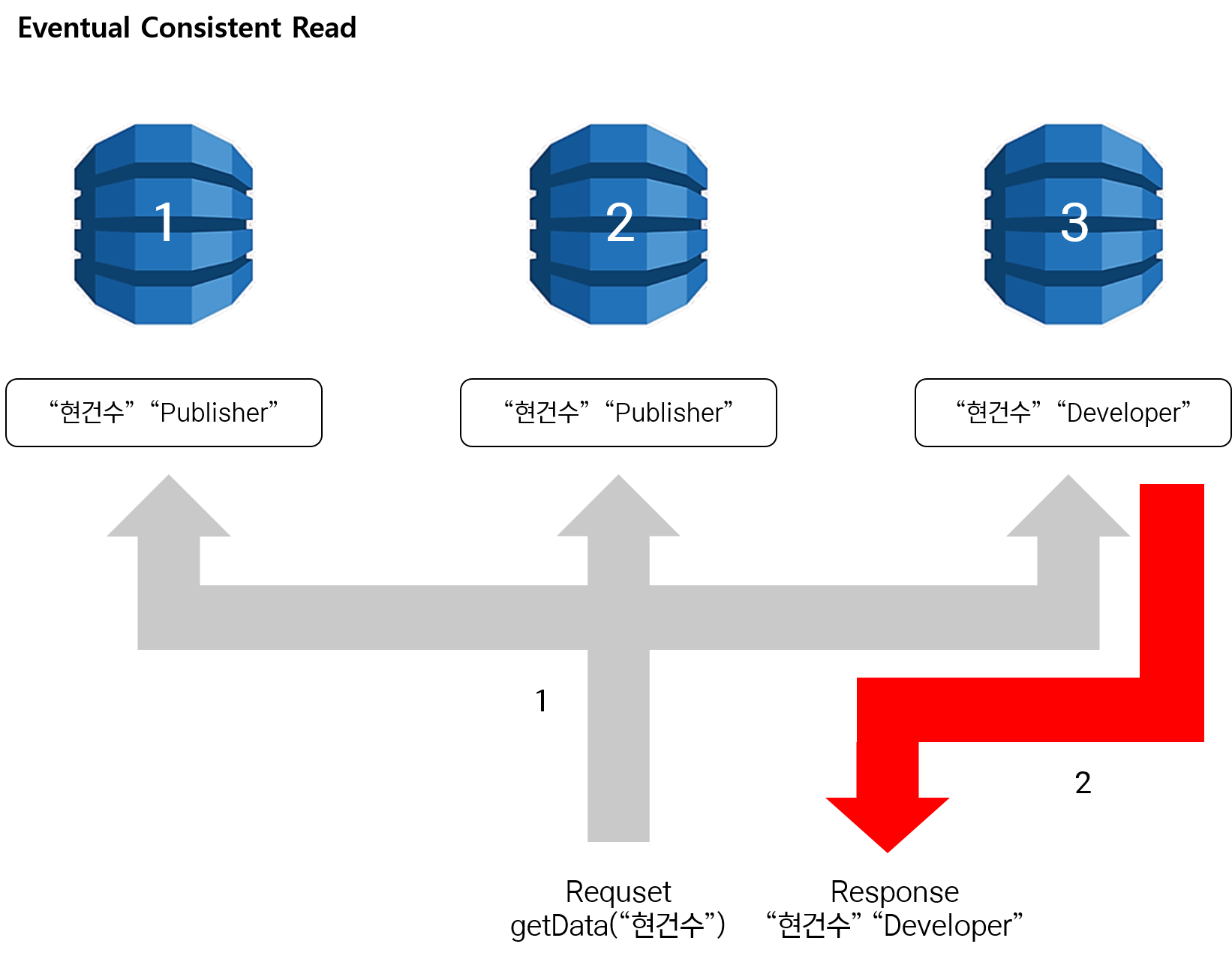
3번 DB가 1번과 2번의 DB보다 네트워크 응답 상황이 가장 낫다고 판단될 경우 3번의 DB 데이터를 가져오게 됩니다. 결과적으로 사용자는 “Developer”라는 데이터를 응답 받게 됩니다.
간단하게 정리하면 Eventual Consistent Read는 응답 속도는 빠르지만 최근 완료된 쓰기 작업 결과가 반영되지 않아 최종적인 데이터를 가져오지 않는다는 특징이 있습니다.
Strong Consistent Read
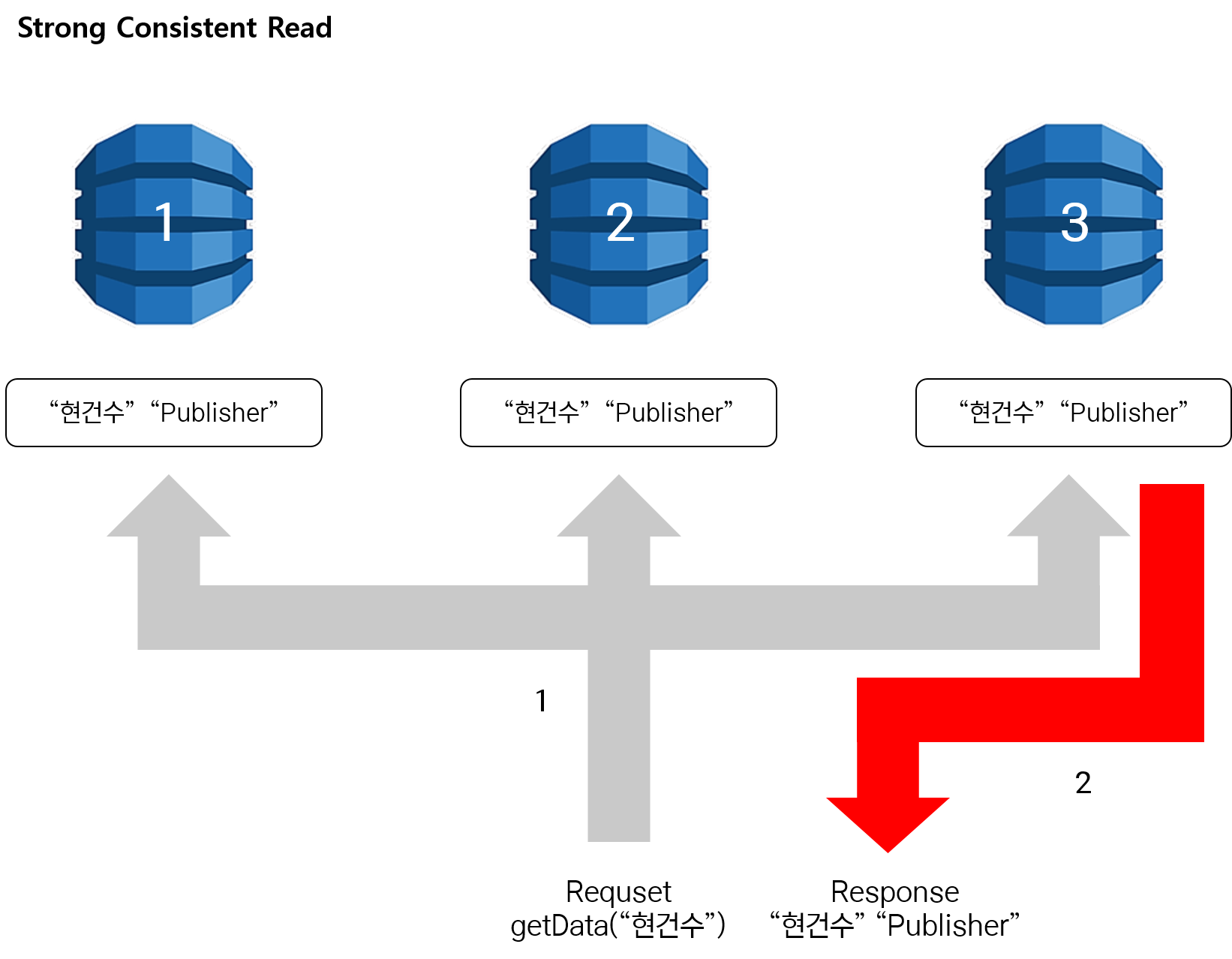
Strong Consistent Read는 Eventual Consistent Read와는 반대로 쓰기 작업이 모두 다 완료한 후 데이터를 응답하는 특징이 있습니다. 그렇기 때문에 “현건수”의 “Developer”를 “Publisher”로 업데이트 하는 중간에 조회 요청이 들어와도 3개의 복제본을 모두 다 업데이트한 후 응답을 “Publisher”로 응답하게 됩니다.
Strong Consistent Read는 응답 속도는 느리지만 최근 완료된 쓰기 작업 결과가 반영되기 때문에 실시간 데이터에 민감한 비즈니스일 경우 Strong Consisntent Read와 Eventual Consistent Read를 적절히 섞어서 사용하면 됩니다. (※ Strong Consistent Read는 GSI를 사용할 수 없기 때문에 PK,SK, LSI를 사용해야하는 점 유의하시길 바랍니다)
4. SQL vs NoSQL
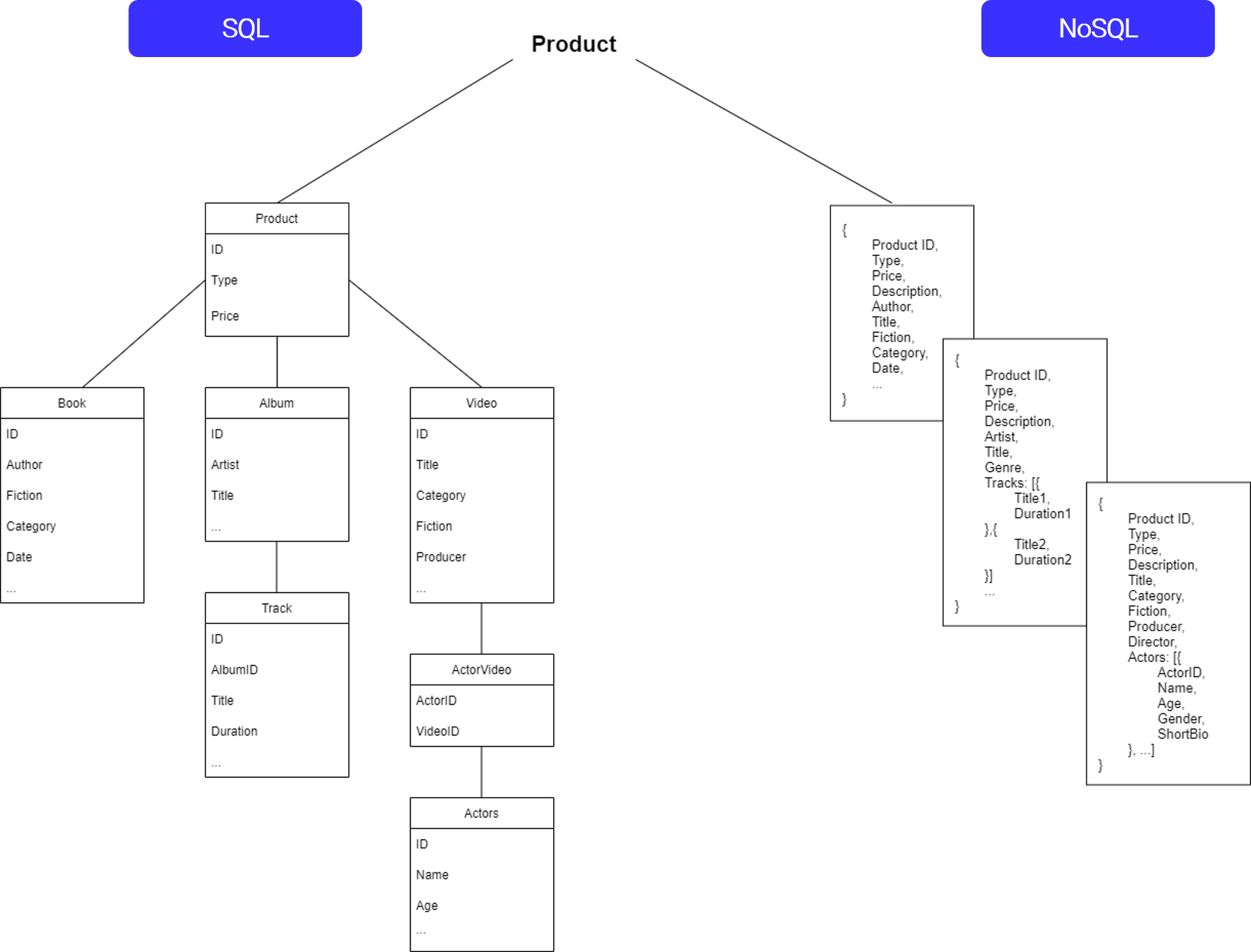
SQL과 NoSQL의 비교를 위해 Product라는 도메인을 RDBMS와 NoSQL의 설계로 나누어봤습니다.
ERD에선 Product 주요 테이블은 Book과 Album, Video와 릴레이션을 맺고 있으며 하위 테이블로도 릴레이션을 맺는 모습을 볼 수 있습니다. 이와 달리 NoSQL에서는 하나의 Item에서 해당 테이블과 릴레이션을 맺는 테이블의 속성이 다 들어가있는 것을 확인할 수 있습니다.
이처럼 ERD와 NoSQL은 확연한 차이가 있으며 NoSQL은 Join을 하지 않고 데이터를 가져올 수 있지만 비정형 데이터라서 어떤 Item에 어떤 속성이 들어가 있는 지 파악하면서 DynamoDB를 설계해야합니다.
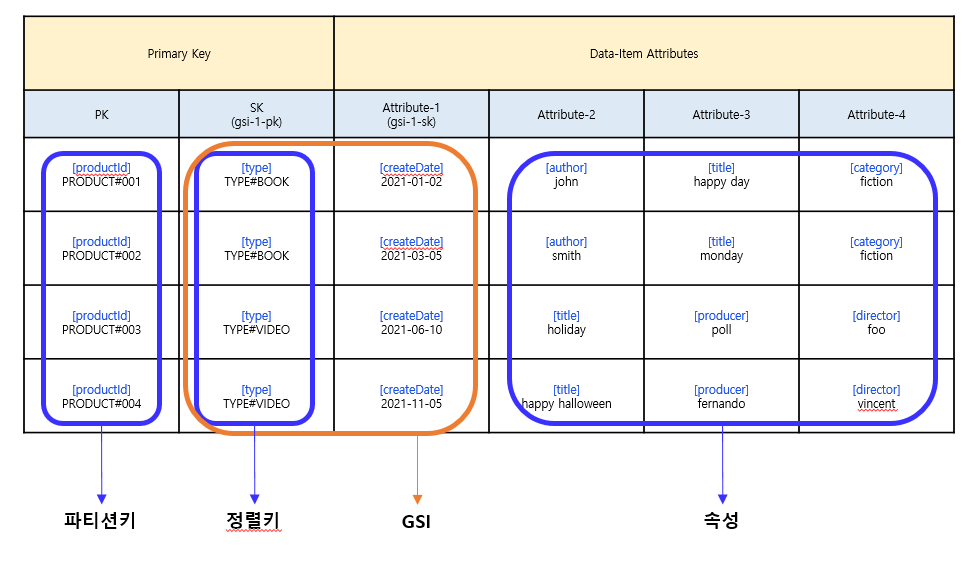
Product을 DynamoDB로 구성해보면,
- Partition Key엔 카디널리티가 높은 속성인 Product 고유 ID 지정
- Sort Key엔 해당 Product의 타입(BOOK, VIDEO 등) 지정
- GSI를 두어 GSI-PK는 테이블의 Sort Key로 지정, GSI-SK는 CreateDate로 지정
이렇게 구성하면 물품 고유 ID로 파티셔닝이 될 것 이고, GSI를 두었기 때문에 TYPE# 별로 물품 목록이 조회가 가능하며 생성 날짜 별로 선택/범위 조회가 가능합니다.
제가 임의의 조회 조건을 설정하여 테이블을 구성하였지만, 실제 DynamoDB 테이블을 설계할 때는 해당 비즈니스에 맞게 Real World 조회 조건을 미리 구성해놓으셔야합니다. RDBMS는 데이터 기반 설계라면 DynamoDB는 쿼리 기반 설계이기 때문에 그만큼 Access Pattern이 더 중요해지고 이 과정에서 기획팀과 수없이 Review → Repeat → Review를 반복해야합니다.
5. DynamoDB Reverse Modeling
줌의 모든 서브 도메인과 서비스의 개인화 데이터를 DynamoDB로 마이그레이션하기 위한 설계과정이며, 바로 DynamoDB를 설계하는 것보다 ERD를 그려나가면서 데이터를 파악하고 Step 별로 ERD → DynamoDB로 Reverse Modeling 하는 방법을 소개합니다.
Reverse Modeling Flow (중요!)
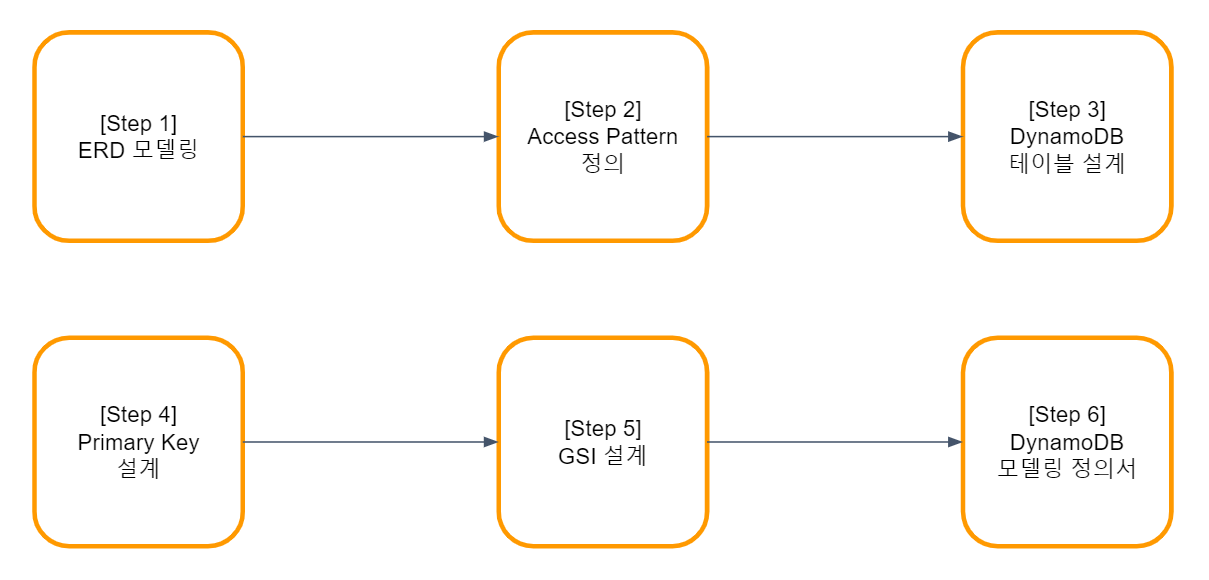
Step 1. ERD 모델링
개발자는 데이터 흐름을 이해하기 위해서는 ERD 모델링부터 구성하는 것이 좋습니다. 왜냐하면 데이터의 관계를 파악하기 용이하며, 바로 DynamoDB를 설계하면 비정형화 된 수많은 Attribute를 추적하기에는 쉽지 않고 테이블이 커져갈수록 개발자 리소스는 커져만 갈 것입니다.
예를 들어, 개인화 데이터를 ERD로 그려보면 아래와 같은 ERD가 구성됩니다.
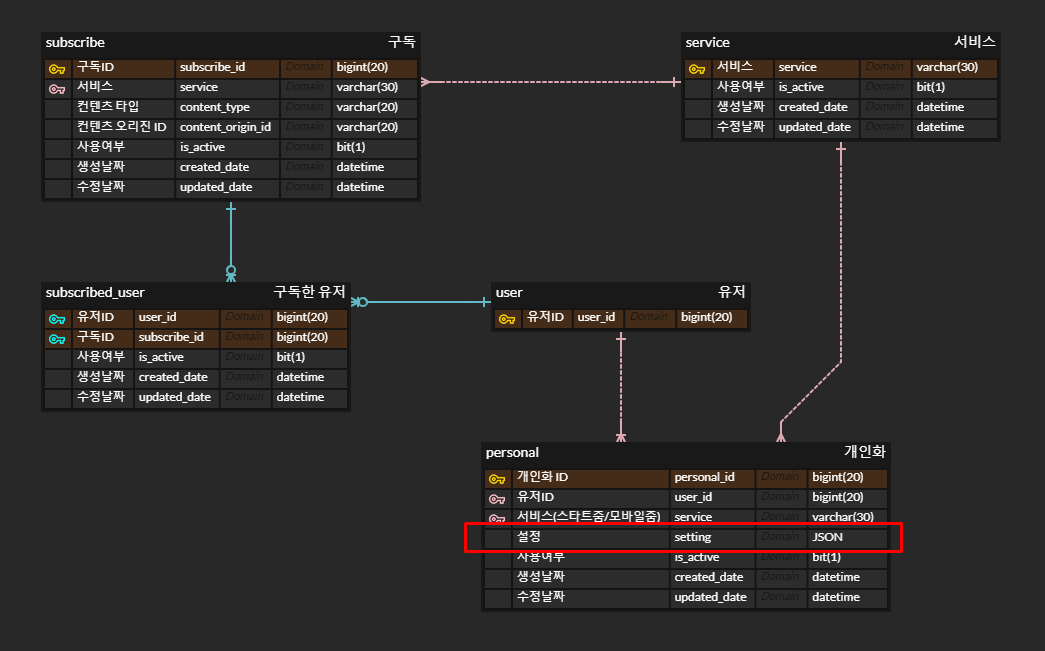
유저, 서비스, 구독, 구독한유저, 개인화 테이블이 존재합니다. 유저는 서비스 별로 개인화 데이터를 가지고 있으며 한 서비스는 여러 컨텐츠를 갖고 유저는 여러 컨텐츠를 구독할 수 있습니다.
개인화 테이블에 “setting”이라는 컬럼을 JSON 타입으로 지정하신 걸 볼 수 있습니다. 테이블로 개인화 데이터를 관리했을 경우 서비스와 기획이 추가될 때마다 테이블이 추가되거나 컬럼이 추가되는 등 스키마가 변경되는 일을 유연하게 막을 수 있는 장점이 있습니다.
Step 2. Access Pattern 정의
개인적으로
가장 중요하다고 생각하는 스텝입니다.RDBMS는 데이터 기반 설계라면, DynamoDB는 쿼리 기반 설계이기 때문에 데이터에 어떻게 Access 할 것인가?에 따라 파티션키, 정렬키, 인덱스의 설계가 모두 바뀌게 됩니다.
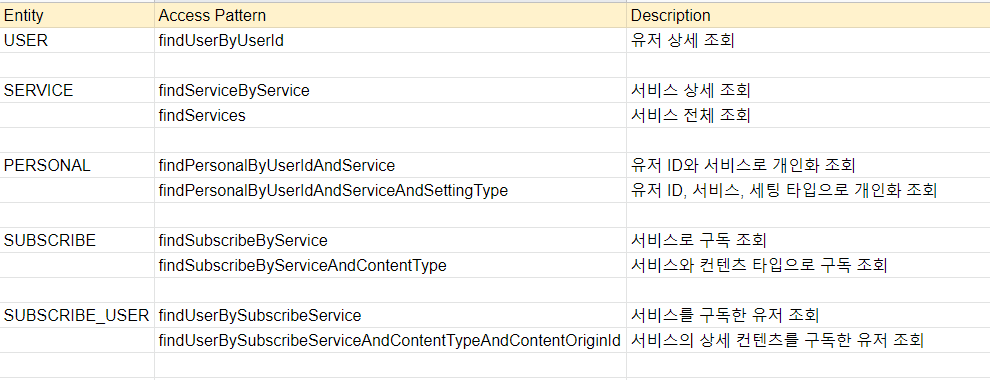
위와 같이 Entity, AccessPattern, Description을 정의합니다. 어떤 엔티티에 어떻게 접근할 것인가를 이번 Step에서 확실히 정하고 가는 것이 중요합니다.
왜냐하면 쿼리 기반인 DynamoDB는 추후에 쿼리 조건과 결과가 바뀔 경우에 이미 정해진 Primary Key Index는 더 이상 변경하지 못 하기에 GSI를 추가 또는 수정 삭제가 불가피하게 됩니다. GSI를 추가하면 되는 거 아니야? 라고 가볍게 생각할 수도 있습니다. 물론 맞는 말씀이지만 GSI를 추가하면 그만큼 인덱스 데이터가 늘어날 것이고 과금 형식을 프로비저닝으로 사용할 경우 읽기와 쓰기 처리량(RCU/WCU)이 인덱스만큼 늘어나기 때문에 그만큼 이 AccessPattern을 가장 중요한 Step으로 생각합니다.
Step 3,4. DynamoDB 테이블 & PK 설계
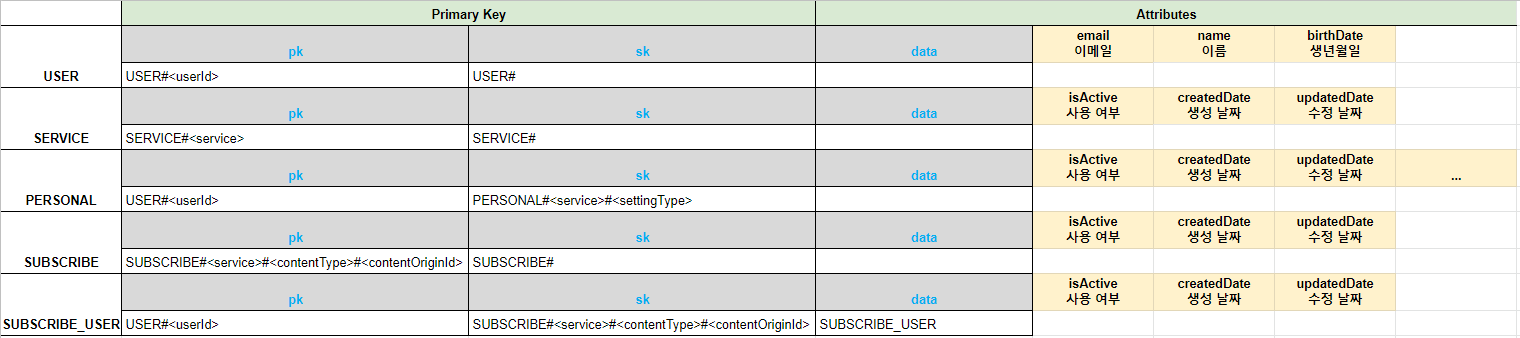
엔티티 기반으로 DynamoDB 테이블과 PK를 설계합니다. 이번 Step부터는 계속 Step 2. Access Patten 정의 를 참고하시면서 작성하시면 됩니다.
USER 엔티티는 userId 라는 고유한 키로 PK를 지정하게 되었고, Access Pattern이 findUserByUserId 이기 때문에 PK에 userId를 파라미터로 두고 Equal 연산으로 접근할 수 있습니다.
SERVICE 엔티티도 마찬가지로 Access Pattern이 findServiceByService 이기 때문에 PK에 service를 파라미터로 두고 Equal 연산으로 접근할 수 있습니다.
PERSONAL 엔티티는 Access Pattern이 findPersonalByUserIdAndService 와 findPersonalByUserIdAndServiceAndSettingType 입니다. findPersonalByUserIdAndService 는 유저아이디와 서비스를 파라미터로 받고 해당 설정 값들을 조회하는 쿼리입니다. 이 경우에는 PK에 userId를 파라미터로 받고, SK에 begin_withs 연산을 이용해 begin_withs(PERSONAL#service)로 접근할 수 있습니다. findPersonalByUserIdAndServiceAndSettingType 쿼리는 PK에 userId를 파라미터로 받고 SK에 PERSONAL#service#settingType 을 파라미터로 받고 Equals 연산으로 접근할 수 있습니다.
SUBSCRIBE 엔티티와 SUBSCRIBE_USER 엔티티는 인덱스를 사용하기 때문에 인덱스를 설명하면서 같이 설명해드리겠습니다.
Step 5. GSI 설계
GSI는 Global Secondary Index로써, Real World에서 모든 데이터를 Primary Key로 Access할 수 없기 때문에 꼭 필요한 인덱스입니다. GSI의 특징은 위에서 설명드렸으니 참고하시길 바랍니다.
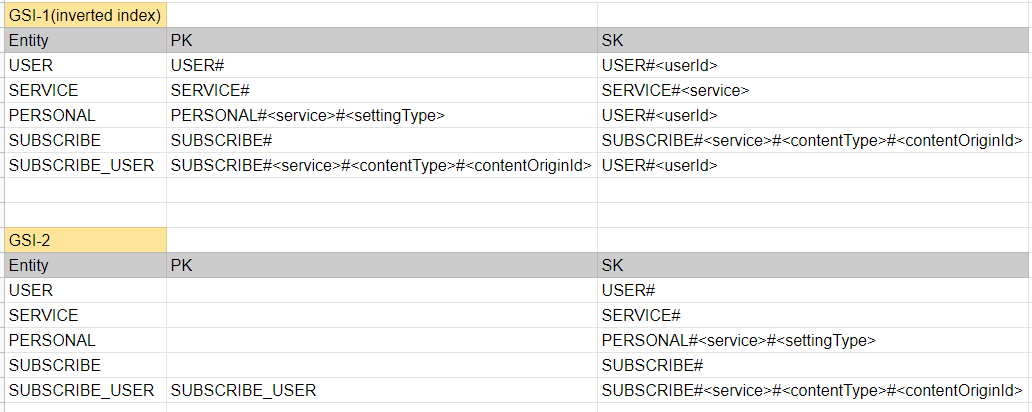
SUBSCRIBE 의 Access Pattern을 확인해보면 findSubscribeByService 라는 서비스로 구독 리스트를 조회하는 쿼리가 있습니다. 이 쿼리를 충족시키기 위해서는 PK의 SUBSCRIBE#<service>#<contentType>#<contentOriginId> 에서 데이터를 접근해야합니다. PK는 분명 Equal연산만 가능한데 어떻게 계층 데이터를 접근할 수 있을까요?
이 해답은 GSI를 활용하는 것입니다.
GSI의 PK를 테이블의 SK로 지정하고, GSI의 SK를 테이블의 PK로 지정하는 것입니다. 위 그림에 적혀있는 것처럼 PK와 SK를 바꾼 inverted index 라고 생각하시면 됩니다. 다시 findSubscribeByService 이 쿼리를 접근해보면 GSI를 활용하여 PK에 SUBSCRIBE#를 주고, SK에 begin_withs(SUBSCRIBE#serivce)로 연산하면 접근이 가능합니다.
SUBSCRIBE_USER 엔티티의 Access Pattern을 확인해보면 findUserBySubscribeService 라는 서비스를 구독한 유저 리스트를 조회하는 쿼리가 있습니다. Primary Key를 확인해보시면 PK에 USER#userId가 있고, SK에 SUBSCRIBE#service#contentType#contentOriginId의 타입이 있습니다. 하지만 이 경우 한 유저의 구독 리스트밖에 조회하지 못합니다.
이 경우에는 Attribute 영역에 data라는 값을 두어서 GSI의 PK로 지정하고, GSI의 SK엔 테이블의 SK를 지정합니다. data 속성엔 SUBSCRIBE_USER라는 값을 넣어서 조회 시 PK에 SUBSCRIBE_USER를 Equals연산하고 SK를 begin_withs연산으로 접근할 수 있습니다.
이처럼 DynamoDB는 쿼리 기반으로 Index와 Primary Key가 변경/추가될 수 있기 때문에 Access Pattern을 팀원들끼리 많은 컨펌과 리뷰를 받으며 정의하고 설계 Flow를 진행하시는 것을 추천드립니다.
Step 6. DynamoDB 모델링 정의서
Attriubutes & Index 정의
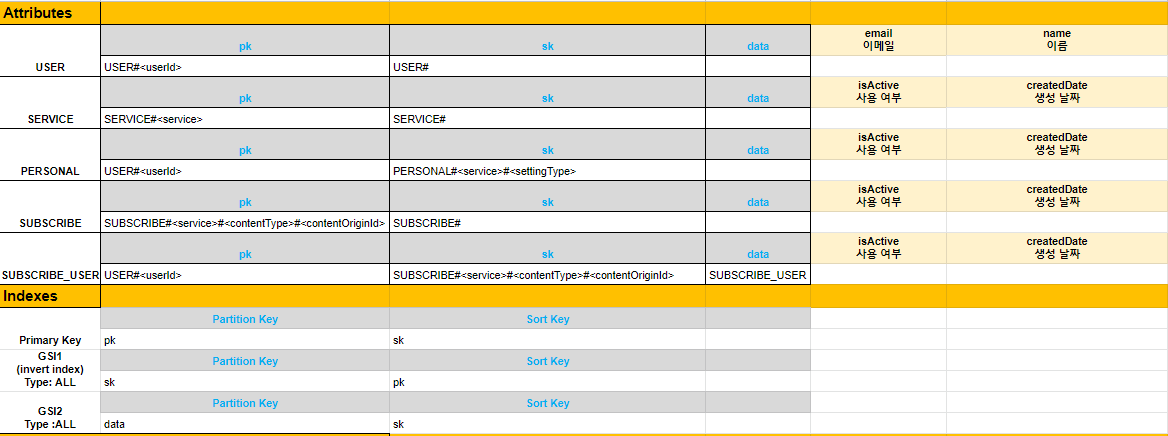
앞서 정의한 DynamoDB 테이블과 Primary Key, Index를 정의합니다.
Primary Key와 GSI가 파티션 키와 정렬키가 어떤 속성인지 정의하고, GSI가 어떤 속성들을 가져올 것인지 정의합니다. 또한 파티션 키 별, 정렬 키 별 가지고 있는 Attributes가 다르기 때문에 정확히 명시해주는 것이 좋습니다.
Query Conditions정의
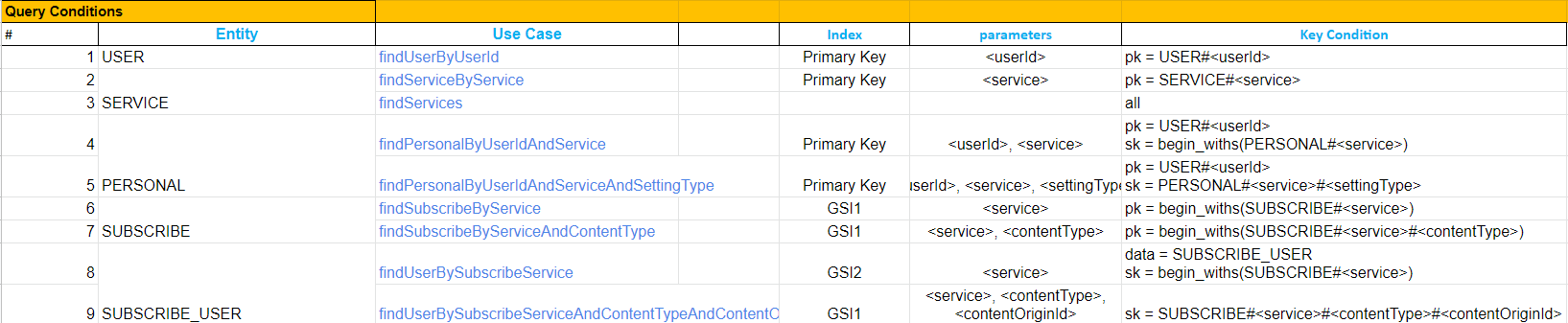
Access Pattern에 맞는 쿼리 조건과 파라미터를 정의합니다.
Primary Key, GSI 중 어떤 인덱스를 사용했는 지 정의하며 PK의 Equal 연산과 SK의 선택, 범위 연산(>,>=,<,<=,begin_withs,between)을 어떤 파라미터를 활용하여 데이터에 접근하는지에 대한 Query Conditions을 정의합니다.
Example Data
USER / SERVICE

여태까지 정의했던 내용을 기반으로 DynamoDB 샘플 데이터를 작성합니다. USER 와 SERVICE 엔티티부터 살펴보겠습니다.
- Index : Primary Key
- PK = PK
- SK = SK
- Query
- select * from USER where pk = USER#userId
USER 엔티티의 PK엔 유저의 고유값을 식별할 수 있는 userId를 예시로 USER#001, USER#002, USER#003 이 들어가 있는 모습을 확인할 수 있습니다. 제가 예시로 001, 002, 003이라는 값을 넣었지만 실제 DynamoDB는 Auto Increament를 지원하지 않기 때문에 고유 식별값으로 파티션 키로 설정할 때 주의하셔야합니다. SK엔 유저 정보를 표현하는 USER#를 넣었고, 현재 Access Pattern에서 GSI를 사용하지 않아도 되기 때문에 data 속성을 빈 값으로 두고 이메일, 이름, 성별 등 나머지 속성들이 적재된 걸 확인하실 수 있습니다. USER엔티티의 Access Pattern을 확인해보면 findUserByUserId 이기 대문에 userId를 PK로 Equal 연산하여 데이터에 접근할 수 있습니다.
- Index : Primary Key
- PK = PK
- SK = SK
- Query
- select * from SERVICE where pk = SERVICE#service
SERVICE 엔티티의 PK엔 줌의 서비스를 표현하는 스타트줌, 모바일줌, 뉴스, 금융이 들어가 있는 모습을 확인할 수 있습니다. SK엔 서비스 정보를 표현하는 SERVICE#를 넣었고, 서비스도 마찬가지로 GSI를 사용하지 않기 때문에 data 속성을 빈 값으로 두고 나머지 속성들을 배치했습니다. Access Pattern을 확인해보면 findServiceByService 이기 때문에 service를 PK로 Equal 연산하여 데이터에 접근할 수 있습니다.
PERSONAL

이번엔 JSON 타입으로 설정한 PERSONAL 엔티티입니다. SK를 확인해보시면 서비스별 설정 타입이 있는데 설정 타입별로 Attributes가 달라지는 것을 확인할 수 있습니다. 이렇게 설계하게 되면 잦은 기획에 변경에도 유연하게 설정 값을 대응할 수 있습니다.
- Index : Primary Key
- PK = PK
- SK = SK
- Query
- select * from PERSONAL where pk = USER#userId and sk = bigin_withs(PERSONAL#service)
PERSONAL 엔티티의 PK엔 유저 고유값이 세팅되어 있는데, Access Pattern을 확인해보면 findPersonalByUserIdAndService 이기 때문에 userId를 PK로 Equal 연산 후 SK의 begin_withs(PERSONAL#service) 연산으로 데이터에 접근할 수 있습니다.
SUBSCRIBE / SUBSCRIBE_USER

이번엔 각 서비스 별 구독 정보를 담고 있는 SUBSCRIBE 엔티티와 유저가 구독한 정보를 담고 있는 SUBSCRIBE_USER 엔티티입니다.
- Index : GSI-1 (inverted index)
- PK = SK
- SK = PK
- Query
- select * from SUBSCRIBE where pk = SUBSCRIBE# and sk = begin_withs(SUBSCIRBE#service)
SUBSCIRBE 엔티티의 Access Pattern이 findSubscribeByServiceAndContentType 인 것을 확인할 수 있습니다. SUBSCRIBE#service#contentType#contentOriginId를 PK로 가지고 있기 때문에 GSI(inverted index)를 이용해서 GSI-PK엔 테이블의 SK를 SUBSCRIBE#로 Equal 연산하고 GSI-SK엔 테이블의 PK를 begin_withs(SUBSCRIBE#service#contentType) 연산하여 원하는 service, contentType 별 계층 데이터를 접근할 수 있습니다.
- Index : GSI-2
- PK = data
- SK = SK
- Query
- select * from SUBSCRIBE_USER where pk = SUBSCRIBE_USER and sk = begin_withs(SUBSCIRBE#service)
SUBSCRIBE_USER 엔티티의 Access Pattern이 findUserBySubscribeService 이므로 한 서비스를 구독하는 유저 리스트를 조회해야합니다. 그렇게 하기 위해선 GSI를 이용하여 data에 SUBSCRIBE_USER를 적재하고 SK에 SUBSCRIBE#service#contentType#contentOriginId를 적재하여 계층 데이터를 접근할 수 있습니다. GSI-PK엔 data 속성을 SUBSCRIBE_USER를 Equal 연산하고 GSI-SK로 테이블의 SK를 begin_withs(SUBSCRIBE#service) 연산하여 SUBSCRIBE 엔티티와 마찬가지로 원하는 service, contentType 별 계층 데이터를 접근할 수 있습니다.
마치며
팀 내 처음으로 도입하는 DynamoDB의 설계 및 리뷰를 맡게 돼서 영광이었습니다.
RDBMS만 주로 사용하다가 NoSQL을 조금이나마 깊게 공부하게 된 건 처음이라 감회가 새로웠고 NoSQL을 바로 설계하는 것이 아니라 ERD에서 DynamoDB로 Reverse Modeling을 진행했던 것이 새로운 경험이었습니다.
개인적으로 DynamoDB를 설계하고 작성하는 내내 느낀 점인데, RDBMS는 데이터 기반 설계라면 DynamoDB는 쿼리 기반 설계라는 것이 모델링 내내 와닿았습니다. 설계 도중 Access Pattern이 바뀌면 뒤에 설계한 PK, SK, GSI가 변경되는 마법을 몸소 체험했습니다. 운영 중 변경되는 요구사항엔 추가/변경이 불가피하지만 최대한 Access Pattern 부분은 많은 리뷰와 피드백을 받고 진행하시라고 말씀드리고 싶습니다.
NoSQL은 스키마 문서 관리는 DB ERD보다 더 확실하게 관리가 필요하다고 생각합니다. 대부분 Key, Value 형식이라고 해서 운영 스토리지를 보면 어떤 데이터가 어떤 구조로 되어 있는지 확인이 매우 어렵습니다. 특히나 운영 스토리지인 경우는 건드리기가 매우 고민이 됩니다. 그렇기 때문에 반드시 문서 관리를 잘해야 한다고 생각 합니다.
위에 제안한 모델링 flow는 개발자들은 ERD에 친숙하기 때문 입니다. 또한 기존 데이터 들이 DB로 되어 있고 NOSQL로 전환을 검토하는 경우가 많습니다. 그런 의미에서 DDB 모델링 flow는 많은 도움이 될 것으로 생각합니다.
마지막으로 NoSQL을 사용하는 경우는 비즈니스 요건이 다양하게 수시로 바뀌는 데이터는 RDB Sharding이 적합하다고 생각하며 NoSQL은 구축 시 쿼리 패턴이 초기 변경이 최소화 되어야 합니다. 그렇기 때문에 기획팀과 많은 요구사항을 사전에 정의가 필요합니다. 그렇지 않을 경우는 NoSQL 선택이 맞는지 다시 한번 검토가 필요합니다.
부족한 글이지만 제 글을 읽고 많은 분들에게 도움이 되면 좋겠습니다. 긴 글 읽어주셔서 감사합니다!

Comments