22 min to read
검색 데이터 서빙 플랫폼 구축
![]()
사용자에게 검색 서비스를 제공하려면 검색 대상이 될 문서에 대한 색인(indexing) 과정과 사용자가 요청하는 쿼리(query), 즉 검색 내용에 대해 일치하는 결과 문서를 제공해야 합니다. 이때 사용자에게는 언제든지 문제 없이 실시간 서비스를 제공해야 합니다. 이러한 검색 서비스를 제공하기 위해 진행했던 개발 과정에 대해 소개합니다.
1. 프로젝트 개요
본 프로젝트는 줌인터넷 신규 입사자로서 진행했던 파일럿 프로젝트로 주요 목적은 검색 대상 문서에 대해 색인하여 서빙하는 플랫폼을 구축하고 사용자가 요청하는 쿼리에 대해 적절한 문서를 검색할 수 있는 서비스를 제공하는 것 입니다.
요구사항
1. Solr 검색엔진 서버 구축
- solr 검색엔진 cluster 구성
- 검색 대상 문서에 대한 solr 스키마 설계
2. Kafka 데이터 파이프라인 구축
- 검색 대상 문서에 대한 색인 필드 추출 및 가공, 색인 배치 처리 작업
- kafka 클러스터에 대해 가공한 문서를 producing, consuming 처리
3. 검색 API 서버 구축
- 기본 검색 기능
- 특정 시간 범위 검색 기능
- 필터 검색 기능
사용 기술 스택
- 언어
- JDK 11
- 프레임워크
- Spring Boot 2.6.3
- Kafka 2.8.0
- Solr 8.6.3
- 라이브러리
- Lombok
- JUnit 5
- Log4j2 2.17.1
- 프로젝트 환경
- Gradle 7.3.3
2. 설계
파일럿 프로젝트에서 요구하는 내용에 따라 검색 서비스를 제공하기 위해 설계했던 내용들을 소개합니다.

Apache Solr 란?
프로젝트의 설계 내용을 소개하기 앞서 먼저 이번 파일럿 프로젝트에서 가장 핵심이 되는 기술인 아파치 솔라에 대해 먼저 설명하겠습니다.
아파치 솔라는 아파치 루씬 기반의 검색 기능을 제공하는 오픈소스 프레임워크 입니다. 특징은 검색 서버로서 REST API를 통해 사용자에게 다양한 기능을 제공하며 JSON, XML, CSV, HTTP Request 등 다양한 데이터 타입에 대한 색인이 가능합니다. 또한 검색한 데이터를 JSON, XML, CSV, 바이너리 타입으로 결과를 응답해줄 수 있습니다. 성능 테스트를 하였때 색인된 문서에 대한 검색 속도가 다른 검색 프레임워크들 보다 조금이지만 더 빠른 장점이 있었고 Solr 4 버전부터 제공하는 Solr Cloud 기능을 통해 확장성(scalability) 있는 시스템 구조를 제공합니다.
전체 시스템 구조
파일럿 프로젝트에서 프로젝트 요구사항에 맞게 검색 서비스를 제공하기 위해서 어떻게 시스템 구조를 설계하였는지 소개하겠습니다.
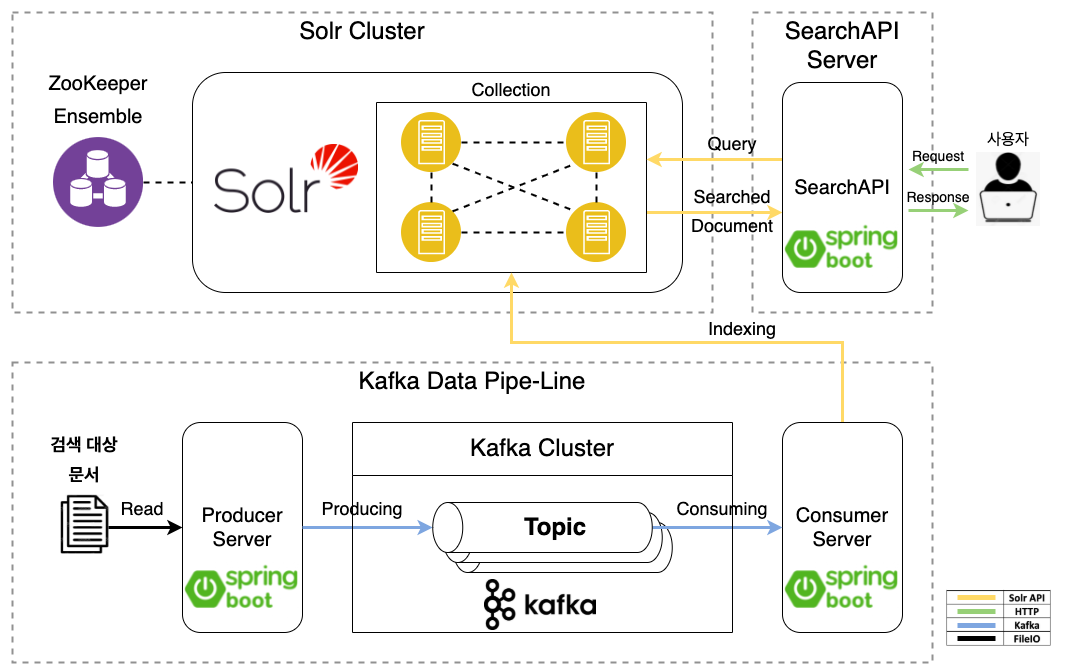
전체 시스템 구조는 크게 요구사항에 따라 다음의 3개 파트로 나눌 수 있습니다.
- Solr Cluster
- Kafka Data Pipe-Line
- SearchAPI Server
데이터 흐름 방향 순으로 설명하겠습니다. 먼저 검색 대상 문서에 대해 파싱 한 뒤 색인할 정보만 데이터를 가공하여 Kafka 클러스터의 타겟 topic에 데이터를 producing 처리하는 Producer Server가 있습니다.
그리고 Kafka 클러스터의 타겟 topic의 데이터를 consuming 처리하는 Consumer Server가 있습니다. Consumer Server는 데이터를 읽은 후에 Solr 클러스터로 색인(indexing)하는 작업까지 수행하게 됩니다.
마지막으로 사용자와 Solr 클러스터 사이에 소통을 도와주는 Search API Server가 있습니다. Search API Server는 사용자로부터 HTTP Request를 받으면 Solr 클러스터에 사용자 쿼리를 전달하여 사용자가 요청한 쿼리에 대해 적절한 문서가 있다면 해당 데이터를 응답해줍니다.
Solr 클러스터 구조
전체 시스템 구조에서 Solr에 대한 클러스터 구조를 확장성 있게 구성하기 위해 어떤 방식으로 설계하였는지 소개하겠습니다.
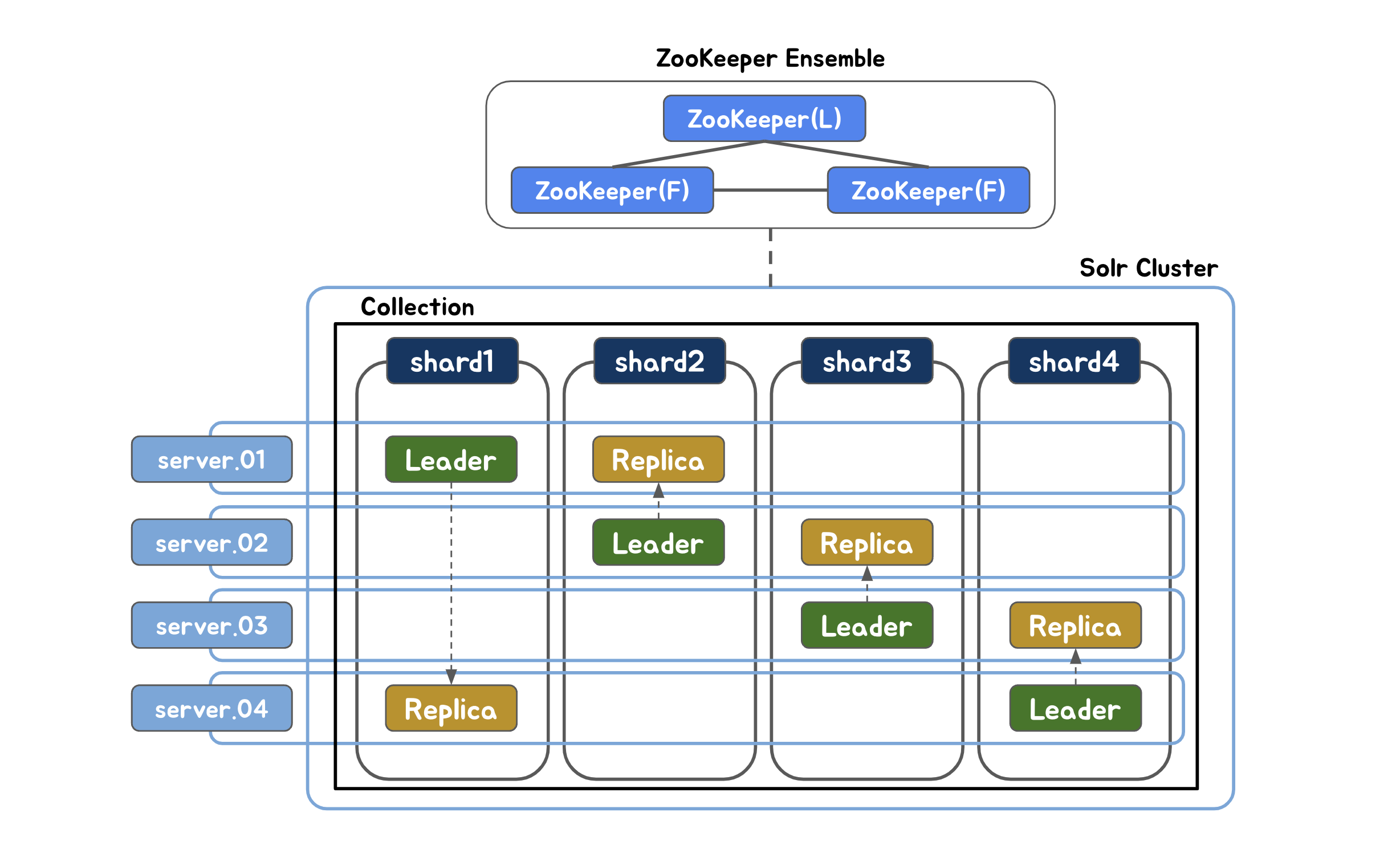
먼저 Solr Cloud 모드를 통해 4대의 서버를 하나의 논리 파티션인 Collection으로 클러스터링하여 분산 처리하도록 구성하였습니다. 그리고 고가용성을 제공하기 위해 Leader와 단일 Replica를 서로 다른 서버에 구성하여 Leader 노드가 장애 발생 시 Replica가 Leader를 대신하여 장애 극복(failover)이 가능합니다.
이때 Solr Cloud 모드를 사용하려면 ZooKeeper가 필요하기 때문에 서버 3대를 사용하여 ZooKeeper Ensemble을 구성하였습니다. ZooKeeper는 각 Solr 노드에 대한 고가용성, 상태체크 등의 기능을 제공해줍니다.
따라서 Solr 검색엔진은 장애 발생 시에도 실제 서비스에 문제 없이 서비스를 제공할 수 있습니다.
ZooKeeper Ensemble은 ZooKeeper 자체적으로도 고가용성을 유지하기 위한 기능입니다.
Replication 설계
다음으로는 Solr 클러스터에서 Replication 타입을 설계한 방식에 대해 소개하겠습니다.
Solr Cloud 모드는 NRT, TLOG, PULL 총 3가지의 복제 타입을 제공합니다. 제공되는 복제 타입에 따라 Leader와 Replica는 다른 복제 정책을 적용하게 됩니다. 상황과 용도에 따라 어떤 타입이 최적일지 개발자가 고민해야 하기 때문에 저는 주어진 요구사항에 따라 제가 조사하고 생각한 이점들을 통해 NRT 타입이라는 복제 방식을 사용하기로 결정하였습니다.
NRT(Near Real Time) 복제 타입 특징
- 실시간으로 색인한 문서에 대해 검색할 수 있게 제공하는 복제 방식
- Leader의 데이터를 항상 Replica에게 복제하여 복제본이 최신 데이터를 유지
- Solr 에서 Default로 제공하는 복제 방식
NRT 타입은 문서에 대한 업데이트 요청이 많이 발생할수록 복제 시간이 많이 소모되어 성능이 자칫 저하될 수 도 있다는 단점이 있습니다. 하지만 모든 복제본이 항상 Leader 의 데이터를 최신 데이터로 유지하고 있기 때문에 장애 복구에 대한 성공 확률이 높아져 좀 더 안전한 시스템을 구축할 수 있습니다.
또한 프로젝트 요구사항으로 주어진 검색 대상 문서의 특징은 실시간으로 문서가 추가되고 추가된 내용에 대해 실시간 검색이 가능해야 한다는 점이 적합한 타입이라 생각하였기 때문에 3가지 타입 중 NRT 타입을 선택하게 되었습니다.
추가로 NRT 타입에서 데이터를 복제하는 주기를 설정에 따라 변경이 가능하여 시스템에 맞도록 설계가 가능한 장점이 있습니다.👍
Solr 스키마 설계
설계 부분의 마지막으로 Solr 컬렉션에 대한 스키마를 어떻게 설계하였는지 간략하게 소개하겠습니다.
본 파일럿 프로젝트의 핵심 기능으로 검색 대상 문서를 사용해 프로젝트 요구사항에 따라 검색 API를 사용자에게 제공해야 합니다. 현재 필요한 기능은 기본 검색, 시간 구간 검색, 필터 검색입니다.
저는 먼저 검색 대상 문서에서 부분 식별 검색이 필요한 항목과 전체 식별 검색이 필요한 항목 두가지 분류를 나눴습니다.
부분 식별로 검색하는 정보들은 검색 대상 문서의 제목이나 내용으로 기본 검색 기능을 제공할 때 사용하였습니다. 이때 검색 대상 문서의 내용을 공백이나 구분점(',' 같은) 기준으로 토큰화하는 분석기를 적용하여 색인하기 때문에 사용자의 입력 키워드에 대한 부분 검색이 가능합니다.
입력 키워드에 대한 부분 검색이란 “검색 구축”으로 사용자가 검색하였을 때, “검색”과 “구축”이 들어간 문서에 대한 검색을 말합니다.
전체 식별로 검색하는 정보들은 별도의 토큰화 작업 없이 내용 자체만으로 식별하는 정보이기에 따로 데이터를 가공하지 않고 특정 시간 대의 구간이나 특정 식별 정보로 필터링할 때 사용하였습니다.
검색 대상 문서에 대해 부분 식별과 전체 식별로 적용한 결과 예시는 다음과 같습니다.
ex) 검색 대상 문서 내 텍스트 입력 값 : 검색 데이터 서빙 플랫폼 구축
부분 식별 적용 결과
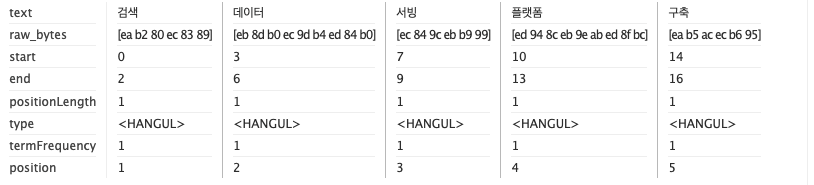
전체 식별 적용 결과

3. 구현
프로젝트 요구사항에 맞는 기능을 제공하기 위해 개발한 Producer Server, Consumer Server, Search API Server의 구현 내용에 대해 소개하겠습니다.
Producer Server
Producer Server는 XML, JSON 등의 타입인 raw 데이터를 읽어서 색인에 필요한 데이터들을 가공한 뒤 Kafka 클러스터에 producing 처리를 합니다.
Producer Server Data Flow
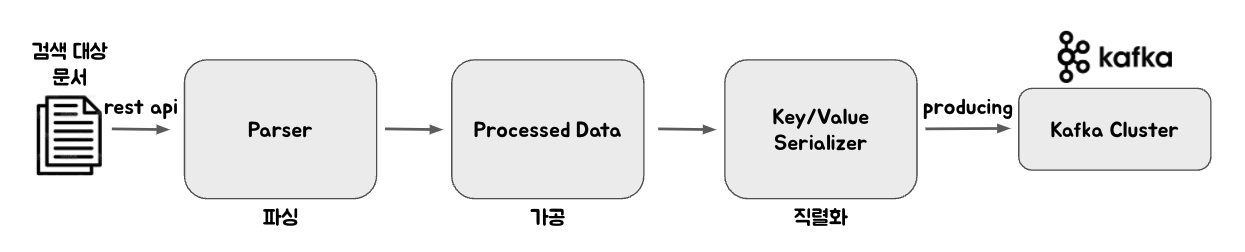
- Producer Server 기능
- REST API로 producing 하기 위한 파일 및 디렉터리 요청
- raw 데이터 파싱 및 데이터 가공
- 데이터 직렬화 후 Kafka 클러스터에 produce 처리
KafkaConfig
KafkaConfig 클래스는 Kafka의 설정을 위한 클래스로 다음의 코드는 KafkaConfig 내부의 Kafka 클러스터에 producing 하기 위한 KafkaTemplate의 옵션 설정 코드 입니다.
@Bean
public ProducerFactory<String, ProcessedData> producerJsonFactory() {
Map<String, Object> configs = new HashMap<>();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress);
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
configs.put(ProducerConfig.RETRIES_CONFIG, RETRY_COUNT);
configs.put(ProducerConfig.ACKS_CONFIG, ASK_LEADER_RECEIVCED_CHECK);
JsonSerializer<Object> valueSerializer = new JsonSerializer<>();
valueSerializer.setAddTypeInfo(false);
return new DefaultKafkaProducerFactory(configs,
Serdes.String().serializer(), valueSerializer);
}
@Bean
public KafkaTemplate<String, ProcessedData> kafkaJsonTemplate() {
return new KafkaTemplate<>(producerJsonFactory());
}
Key는 String, Value는 Json 타입으로 직렬화하였고 재시도 설정 옵션과 데이터 요청 확인 옵션을 Kafka 클러스터 브로커의 Leader 까지만 요청 확인 설정을 하여 데이터 전송에 대해 안전을 보장하였습니다.
KafkaProducerService
KafkaProducerServer는 입력 받은 파일에 대해 파싱하고 KafkaTemplate을 사용해 Kafka 클러스터로 전송하는 서비스를 제공합니다.
다음 보여드리는 KafkaProducerService 클래스 내부 코드는 파일이나 디렉터리를 대상으로 파싱한 뒤 Kafka 클러스터에 전송하는 동작을 수행합니다.
public String processFileToProcessedData(
String filePath, Class<? extends Parser> parserType)
{
Parser parser = Parser.getParserInstance(parserType);
List<ProcessedData> processedDataList = null;
try {
processedDataList = parser.doParsing(filePath);
} catch (Exception e) {
log.error("processFileToProcessedData() parser.servingParser Exception");
}
if (processedDataList == null || processedDataList.size() == 0) {
log.info("processFileToProcessedData() parsing data is null OR zero");
return null;
}
for (ProcessedData data : processedDataList) {
// KafkaTemplate을 사용하여 데이터 Producing 처리 진행
sendMessage(data);
}
return filePath;
}
public List<String> processDirectoryToProcessedData(
String directory, Class<? extends Parser> parserType)
{
if (directory == null || directory.isBlank()) {
log.info("processDirectoryToProcessedData() directory is null OR Blank");
return null;
}
List<String> successFiles = new ArrayList<>();
File dir = new File(directory);
// 입력 받은 디렉터리 내부 파일들 순회하며 파싱 후 전송 작업 수행
for (File file : Objects.requireNonNull(dir.listFiles())) {
successFiles.add(processFileToProcessedData(String.valueOf(file), parserType));
}
return successFiles;
}
processDirectoryToProcessedData() 메서드에서 디렉터리 경로를 입력 받으면 해당 경로의 디렉터리 내부 파일들을 순회하면서 하나씩 파싱 작업을 수행합니다. 이때 사용자가 요청한 parserType, 즉 파일의 형태에 따라 맞는 parser 인스턴스를 만들어 doParsing() 메서드에 파일을 넘겨 파싱 작업을 수행합니다.
파싱 작업이 끝난 가공된 데이터 리스트는 KafkaTemplate으로 Kafka 클러스터에 producing 처리를 합니다. 성공한 파일은 그대로 파일명을 리턴하여 사용자에게 성공 유무를 확인시켜줍니다.
Consumer Server
Consumer Server는 Kafka 클러스터에서 데이터를 consuming 한 뒤 Solr 클러스터에 색인 처리를 합니다.
Consumer Server Data Flow

- Consumer Server 기능
- Kafka 클러스터에서 데이터 consume 처리
- Consume 한 데이터를 역직렬화 후 Solr Document 타입으로 가공
- Solr Cluster의 collection으로 색인 처리
KafkaConsumerService
KafkaConsumerService는 @KafkaListener 어노테이션을 사용하여 Kafka 클러스터에 타겟 topic의 데이터를 consuming 한 뒤, Solr에 색인하기 위한 문서 타입으로 변환을 합니다. 그리고나서 변환한 데이터를 Solr 클러스터로 색인 요청을 합니다.
@SuppressWarnings("unchecked")
@KafkaListener(topics = "{TARGET_TOPIC_NAME}", groupId = "1",
containerFactory = "kafkaListenerJsonContainerFactory")
public void consume(Map<String, Object> receivedData) {
if (receivedData == null) {
log.error("Consumed ReceviedData is null");
return;
}
log.info("Consumed ReceviedData {}", receivedData);
solrService.save(
convertMapToSolrInputDocument((Map<String, Object>) receivedData.get("data"))
, RETRY_COUNT);
}
KafkaListenerJsonContainerFactory
KafkaListenerJsonContainerFactory() 메서드에서 Kafka의 KafkaListener에 대한 ConsumerFactory 설정과 CallBack 설정을 합니다.
@Bean
public ConcurrentKafkaListenerContainerFactory<String, Map<String, Object>>
kafkaListenerJsonContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, Map<String, Object>> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerJsonFactory());
factory.setRetryTemplate(retryTemplate());
factory.setRecoveryCallback(context -> {
log.info("consumer retry count:{}, contents:{}, exception:{}"
, context.getRetryCount(), context, context.getLastThrowable());
return null;
});
return factory;
}
이때 consume 실패에 대한 재시도를 모두 실패하였을 때 recovery callback이 호출되는데 이번 프로젝트에서는 간단한 로깅 처리만 하고 recovery 처리는 향후 개선 작업으로 계획하였습니다.
SolrConfig
Solr 클러스터에 연결하기 위한 클라이언트 설정에 관한 코드입니다.
@Bean
public CloudSolrClient cloudSolrClient() {
String[] zkPaths = zkPath.split(",");
List<String> zkServers = new ArrayList<>(Arrays.asList(zkPaths));
zkServers.forEach(s -> log.info("zkServer List: {}", s));
CloudSolrClient solrClient = new CloudSolrClient.Builder(zkServers,
Optional.empty())
.withConnectionTimeout(10000)
.withSocketTimeout(60000)
.build();
return solrClient;
}
CloudSolrClient 클래스는 SolrCloud 모드에서 각 Solr 노드와 통신하기 위한 클래스로 ZooKeeper의 호스트 정보를 받아와 Builder에 등록을 하면 ZooKeeper를 통해 Solr 클러스터에 등록된 Solr 노드들을 찾아 통신할 수 있도록 기능을 제공합니다.
이에 따라 색인 과정이나 쿼리 요청 과정에 분산 처리를 위해 CloudSolrClient 클래스를 활용하였습니다.
CloudSolrClient는 각 Solr 노드에 대한 요청을 진행할 때 기본으로 라운드 로빈 방식을 제공하고 있습니다.
SolrService
다음은 Solr 클러스터에 색인하는 코드입니다. solrClient의 add 메서드를 통해 Collection을 지정한 뒤 Solr 문서 타입인 SolrInputDocument 객체 타입으로 색인을 요청합니다. 이때 만약 실패를 하게된다면 재시도를 하고 계속 실패하게 된다면 색인이 불가능한 문서에 대해 에러 로깅을 합니다.
public void save(SolrInputDocument document, int retry) {
UpdateResponse response = null;
try {
for (int i = 0; i < retry; i++) {
response = solrClient.add(CollectionName, document);
if (response != null && response.getStatus() == SOLR_API_SUCCESS) {
break;
}
}
if (response == null || response.getStatus() != SOLR_API_SUCCESS) {
log.error("solr index failed document[{}]", document);
}
} catch (Exception e) {
log.error("solr add API exception retry[{}] document[{}]", retry, document);
}
}
Search API Server
Search API Server는 API를 사용하는 사용자로부터 쿼리를 요청 받으면 쿼리에 대한 유효성 검토 이후 Solr 클러스터에 쿼리 요청을 통해 쿼리에 매칭되는 문서를 사용자에게 다시 응답해줍니다.
Search API Server Data Flow

- Search API Server 기능
- 기본 검색 기능
- 특정 시간 범위 검색 기능
- 필터 검색 기능
SolrSearchApi
사용자에게 REST API를 제공하기 위해 구현한 RestController의 기능별 API 코드입니다.
- 기본 검색 API
사용자로부터 query를 요청 받으면 query에 대해 solrQueryService의 makeSolrQuery() 메서드로 유효성 검증과 SolrQuery 객체로 만들어주는 처리를 하게됩니다. 이후 생성된 SolrQuery를 사용하여 solrSearchService의 executeSolrQuery 메서드 내부에서 Solr 클러스터로 요청을 합니다.
마지막으로 ServingResponse 객체로 래핑하여 사용자에게 결과를 응답합니다(사용자에게 응답하는 과정은 다른 API 모두 동일합니다).
@GetMapping("/query")
public ResponseEntity<ServingResponse> querySelect(
@RequestParam String query
) {
log.info("querySelect() User Input query[{}]", query);
SolrQuery solrQuery = solrQueryService.makeSolrQuery(query);
return ServingResponse(solrSearchService
.executeSolrQuery(solrQuery, REQUEST_QUERY_RETRY_COUNT));
}
- 특정 시간 범위 검색 API
기본 검색 기능에서 말씀드린 내용과 같이 사용자로부터 query를 받아 SolrQuery를 만든 후에 추가로 시간 범위 검색을 위한 시간 구간 값(begin-end)을 SolrQuery 인스턴스에 속성 추가 해줍니다.
@GetMapping("/range_query")
public ResponseEntity<ServingResponse> querySelectBetweenDate(
@RequestParam String query,
@RequestParam @Nullable String begin,
@RequestParam @Nullable String end
) {
log.info("querySelectBetweenDate() User Input begin[{}], end[{}] query[{}]"
, begin, end, query);
SolrQuery solrQuery = solrQueryService.makeSolrQuery(query);
solrQueryService.setFilterQuery(solrQuery, begin, end);
return ServingResponse(solrSearchService
.executeSolrQuery(solrQuery, REQUEST_QUERY_RETRY_COUNT));
}
- 필터 검색 API
마찬가지로 사용자로부터 query를 받아 SolrQuery를 만든 후에 추가로 필터링하기 위한 키워드를 SolrQuery 인스턴스에 속성 추가 해줍니다.
@GetMapping("/query/{filterKeyword}")
public ResponseEntity<ServingResponse> querySelectFilter(
@RequestParam String query,
@PathVariable String filterKeyword
) {
log.info("querySelectFilter() User Input Filter Keyword[{}] query[{}]"
, {FILTER_KEYWORD}, query);
SolrQuery solrQuery = solrQueryService.makeSolrQuery(query);
solrQueryService.setFilterQuery(solrQuery, filterKeyword);
return ServingResponse(solrSearchService
.executeSolrQuery(solrQuery, REQUEST_QUERY_RETRY_COUNT));
}
SolrSearchService
유효한 쿼리에 대해 Solr 클러스터에 쿼리 요청을 처리해주는 서비스 코드입니다.
public SolrDocumentList executeSolrQuery(SolrQuery query, int retry) {
log.info("executeSolrQuery() execute collection:{}, query: {}"
, collectionName, query);
QueryResponse response = null;
try {
for (int i = 0; i < retry; i++) {
response = solrClient.query(collectionName, query);
if (response != null && response.getStatus() == SOLR_API_SUCCESS) {
break;
}
}
} catch (Exception e) {
throw new SolrApiException("executeSolrQuery() query API Failed ErrorMsg["
+ e.getMessage() + "], [query: " + query + "]",
ErrorCode.INTER_SOLR_SERVER_ERROR);
}
if (response == null || response.getStatus() != SOLR_API_SUCCESS) {
log.error("executeSolrQuery() query API Failed query:{}", query);
return null;
}
SolrDocumentList documentList = response.getResults();
if (documentList.size() == 0) {
log.info("executeSolrQuery() query result not found query:{}", query);
}
return documentList;
}
동작은 색인 요청 코드와 같이 재시도 끝에 실패한다면 에러 로깅을 하고 null 값을 리턴합니다. 그리고 Solr 클러스터로부터 응답은 잘 받았는데 적합한 문서가 없다면 간단한 로깅만 하고 결과를 리턴합니다. 이후 사용자에게 결과 값을 응답할 때 null이나 적합한 문서가 없는 경우 204(no content) 상태로 응답하고 적합한 문서가 있다면 문서와 200(success) 상태로 응답합니다.
Search API Server 단위 테스트
Search API Server의 테스트 코드는 EmbeddedSolrServer 객체를 사용하여 임시 Solr 서버를 구동해 Solr API에 대한 단위 테스트를 할 수 있도록 진행하였습니다. EmbeddedSolrServer 객체는 Solr 설정 파일이 있는 Solr 홈 디렉터리만 있다면 어디서든 Solr API에 대한 단위 테스트를 진행 할 수 있습니다.
@TestInstance(TestInstance.Lifecycle.PER_CLASS)
@SpringBootTest
class SolrSearchServiceTest {
private EmbeddedSolrServer server;
private CoreContainer container;
...
@BeforeAll
void setup() {
container = new CoreContainer(EMBEDDED_SOLR_SERVER_PATH, null);
container.load();
server = new EmbeddedSolrServer(container, COLLECTION_NAME);
...
}
@Test
void solrApiSuccessTest() throws SolrServerException, IOException {
QueryResponse response = server.query(solrTestQuery);
assertEquals(SOLR_API_SUCCESS, response.getStatus());
}
@Test
void executeSolrQueryTest() throws SolrServerException, IOException {
SolrDocumentList documentList = solrSearchService
.executeSolrQuery(solrTestQuery, SOLR_API_RETRY_COUNT);
assertNotNull(documentList);
}
...
}
@BeforeAll 어노테이션으로 모든 단위 테스트를 진행하기 앞서 EmbeddedSolrServer에 대한 초기화 및 구동 과정을 진행합니다. 이후 Solr 서버에 대한 API 테스트를 진행합니다.
검색 API 사용 예시
이번에는 실제로 구축한 Search API Server에서 제공하는 API의 사용 예시를 소개하겠습니다.
기본 검색 API
기본 검색 기능은 사용자가 요청한 쿼리, 즉 찾으려는 문서에 대한 검색 키워드에 대한 Solr 검색엔진 내부 매칭 문서를 반환해주는 API 입니다.
curl -X GET IP:PORT/search/query?query={요청쿼리}
API 호출 결과 사용자가 찾으려는 검색 키워드에 적합한 문서를 응답해줍니다.
특정 시간 범위 검색 API
특정 시간 범위 검색은 사용자가 요청한 쿼리에 대한 기본 검색 결과 내에서 추가로 문서의 특정 시간 필드에 대한 시간 범위 검색을 제공하는 API 입니다.
curl -X GET IP:PORT/search/range_query?query={요청쿼리}&begin={시작날짜}&end={끝날짜}
API 호출 결과 요청 쿼리에 매칭되는 문서 중 문서의 특정 시간 필드에 대해 요청한 begin부터 end 사이의 매칭되는 문서들을 응답해줍니다.
필터 검색 API
필터 검색 기능은 사용자가 요청한 쿼리에 대한 기본 검색 결과 내에서 추가로 특정 필드에 대한 키워드를 요청받아 다른 문서는 제외하도록 필터링한 결과를 반환하는 API 입니다.
curl -X GET IP:PORT/search/query/{필터키워드}?query={요청쿼리}
API 호출 결과 요청 쿼리에 매칭되는 문서 중 요청 받은 필터 키워드에 매칭되는 문서들을 응답해줍니다.
4. 검증
검색 서비스를 제공하기 위해 구축한 서버에 성능 테스트를 통해 제대로 설계되었고 구동하는지 검증 과정을 진행하였습니다.
성능 테스트 환경 정보
아래 Solr 클러스터, Search API 서버에 대한 성능 테스트는 모두 공통 스펙을 갖고 있는 4대의 서버에 구축한 뒤 성능 테스트를 진행하였습니다. 사용한 벤치마크 툴과 쿼리는 모두 동일합니다.
- 서버 공통 스펙(4대)
- OS: CentOS 7.2
- CPU: Intel 16-Core
- Memory: 32GB
- Disk
- SSD: Solr 구동 및 문서 색인
- HDD: 프로세스 로그 및 기타 파일 저장
- 벤치마크 툴
- ngrinder
- 사용 쿼리
- 문서의 제목, 본문 내용을 공백 단위로 나눈 문자열 query
Solr 클러스터 성능 테스트 결과
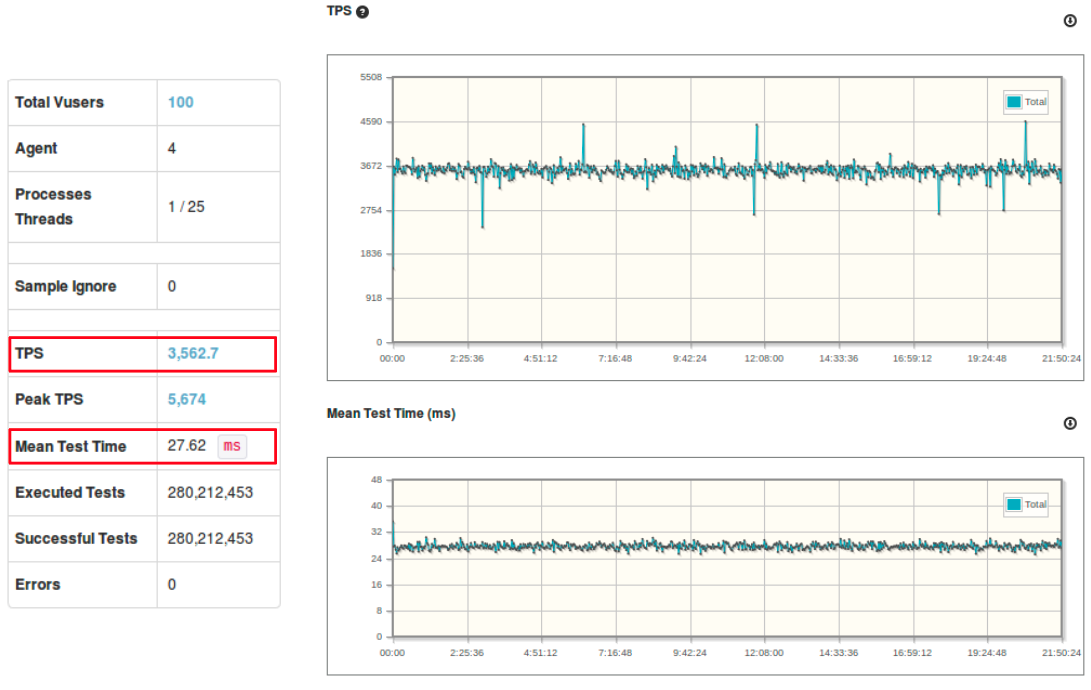
Solr 클러스터에 대한 성능 테스트를 진행한 결과 입니다. TPS는 대략 3500 정도로 측정되었고 MTT는 대략 27 ms 정도로 측정되었습니다.
Search API 서버 성능 테스트 결과
Search API 서버에 대한 성능 테스트를 진행한 결과 입니다. TPS는 대략 3400 정도로 측정되었고 MTT는 대략 28 ms 정도로 측정되었습니다.
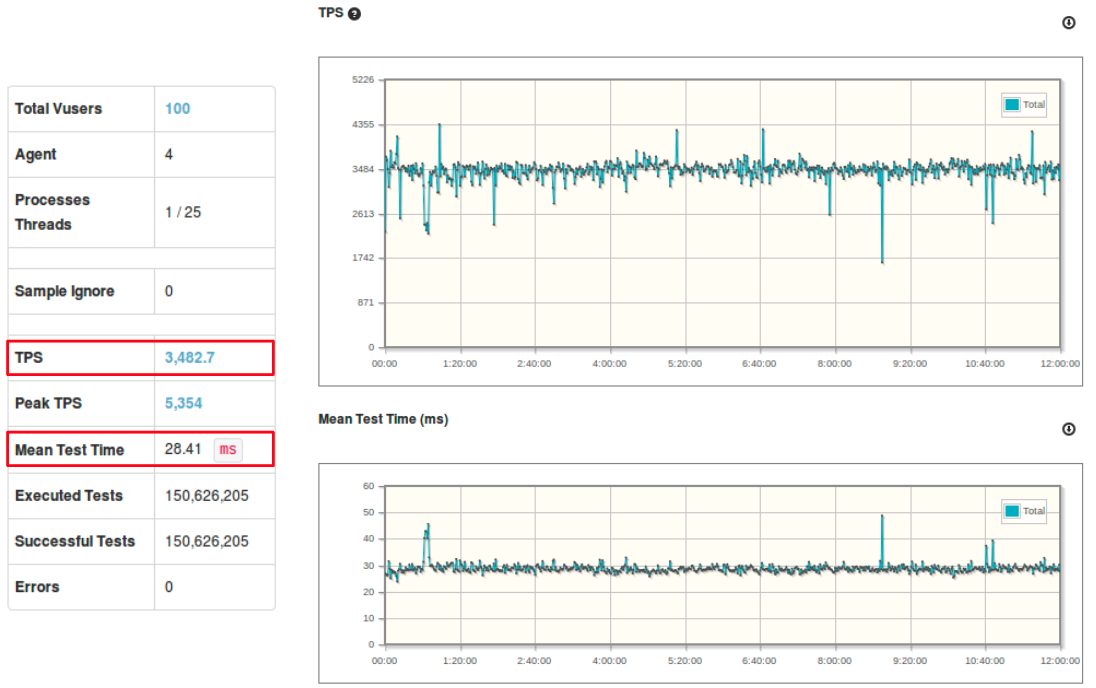
Solr 클러스터와 Search API 서버에 대해 10시간 이상 서버를 구동하며 가상 유저 100명으로 테스트한 결과 문제없이 서비스를 제공한 것을 확인할 수 있었습니다.🙂👍
TPS(Transaction Per Second, throughput, 단위 1’s) : 초당 트랜잭션 처리량 MMT(Mean Test Time, latency, 단위 ms 1/1000’s) : 한 건의 트랜잭션 처리 평균 시간
향후 개선 사항
- Consumer Server
- Kafka 클러스터에서 Consuming 하는 도중 장애 발생 시에 데이터 손실 방지 처리
- 스레드 풀을 활용하여 Consume 작업 병렬 처리
- Solr 클러스터에 문서를 색인하는 도중 장애 발생 시 예외처리
- Search API Server
- 다중 Search API 서버에 대해 scalability, load balance 지원
- Solr 클러스터에 사용자 쿼리 요청 도중 실패에 대한 예외처리
마치며
이번 파일럿 프로젝트를 통해 처음으로 검색 기술과 메시지 큐를 학습하고 직접 다뤄볼 수 있었습니다. 소규모이지만 각각의 파트들이 문제 없이 잘 동작해야 되기 때문에 여러 가지 상황에 대해 고민해야 했습니다. 예를 들어 Solr 클러스터에 문서 색인을 더 빠르게 하는 방법, Kafka를 통해 데이터를 주고 받을 때 데이터 보장을 어떻게 해줄지 그리고 searchAPI server의 경우에는 실제로 사용자가 키워드를 통해 검색할 때 개발자 입장에서는 어떻게 해야 좋은 검색 결과를 줄 수 있을지 등.. 😵💫
좀 더 안전하고 좋은 서비스를 제공하기 위해 이전에는 깊게 생각하지 못했던 것들과 고려해보지 못한 부분들을 더 깊게 생각하게 된 좋은 경험이 되었습니다. 짧은 기간 동안 새로운 기술에 대해 학습하고 혼자서 만들어내는 경험이 많지 않았는데, 작은 성공이지만 이번 과정을 통해 이후 더 큰 성공을 할 수 있는 자신감을 얻게 되었다고 생각합니다. 그리고 동시에 자신의 부족함도 많이 깨닫게 되었습니다.😂
끝으로 파일럿 프로젝트 과정 내내 제 질문에 대해 항상 친절하게 답해주고 결과에 대해 자세한 피드백을 통해 제가 끝까지 파일럿 프로젝트를 잘 마무리 하도록 도와주신 팀원분들 모두 감사드립니다.😊🙏
긴 글 끝까지 읽어주셔서 감사합니다!

Comments